Serviciul
HTTP. Aplicatii Web.
In zilele noastre, cea mai utilizata metoda
de a interactiona cu un server Web este aceea a arhitecturii client/server
bazata pe tehnologie Web. Procesul schimbului de informatii utilizat
in tehnologia Web nu difera de procesul implementat de arhitectura
standard client/server, in care programul server gestioneaza procesarea
interogarilor receptionate de la programele clienti.
In cadrul procesului
de schimb de informatii utilizat de tehnologiile web, programele client
sunt executate in programe de navigare web, care se gasesc de obicei pe
statiile de lucru sub forma aplicatiilor auxiliare, pe post de
clienti. Browser-ele web sunt utilizate pentru vizualizarea si
interpretarea imediata a documentelor web stocate pe server, ca si
pentru acces la alte servicii speciale, precum:
Copierea de fisiere de pe servere FTP
(client FTP);
Oferirea de sesiuni virtuale la server
(Telnet);
Acces prin meniuri la resursele
calculatoarelor de la distanta (Gopher).
Accesul la aceste functii speciale este posibil
tinand cont de faptul ca, inca de la inceput, programele de
navigare web au fost create pentru acces multiprotocol, pentru a oferi o
interfata unica pentru acces la mai multe resurse din
retea. La ora actuala, cele mai cunoscute navigatoare web sunt
Internet Explorer (Microsoft), Opera (Opera) si FireFox (Open Source).
In cadrul schemei de interactiune cu tehnologiile
web, serverul web actioneaza ca un program server principal. Acesta
este lansat pe server si implementeaza procesarea interogarilor
care sunt transmise de catre clienti, interactiunea dintre
clientii web si serverul web fiind indeplinita pe baza regulilor
stabilite de protocolul HTTP (HyperText Transfer Protocol). In momentul
pornirii serverului web, acesta incepe sa "asculte" sau sa controleze
un port logic din retea, care, in mod standard pentru acestea, este cel cu
numarul 80, si presupune ca toate mesajele transmise catre
acest port sunt destinate serverului web.
In momentul receptionarii unei
interogari de la clientul web, serverul web stabileste o conexiune
prin utilizarea TCP/IP si incepe sa schimbe informatii cu
clientul prin protocolul HTTP. In cazul in care clientul doreste acces la
informatii protejate de pe serverul web, serverul poate cere sa fie
introduse un identificator si o parola pentru utilizator, aceste documente
web protejate fiind astfel accesibile doar utilizatorilor cu drepturile de
acces potrivite.
Documentele web receptionate de browser de la
serverul web sunt reprezentate de fisiere text scrise intr-un limbaj
special, numit HTML (HyperText Markup Language), limbaj care consta
intr-un set de "intelegeri" care definesc formatarea textului si cum
va arata acesta in cadrul ferestrei navigatorului web. Marcajele, care
definesc formatarea, controleaza de asemenea cum vor fi afisate
legaturile catre alte obiecte sau catre grafice. In plus
fata de limbajul de marcare, in documentul HTML pot fi inserate
programe scrise in JavaScript si VBScript, programe care vor fi
interpretate doar de catre browserul web in momentul in care documentul
web va fi incarcat si afisat.
Functionarea serverelor
HTTP
Este greu de imaginat
cazul in care administratorul unui server ar dori sa faca disponibil
pentru toata lumea sistemul de fisiere al serverului Web. Deci,
serverele web atribuie un director radacina (root folder) ca
punct de plecare pentru toate cererile GET. Acest termen mai este utilizat
si sub forma de home directory, home folder, root directory, HTTP
root, document root sau home root.
In cazul in care
serverul radacina este
C:Inetpubwwwroot
iar serverul a primit o cerere de tip
GET
/studenti/grupe/abcd/note.html
serverul web va cauta in realitate si va trimite
fisierul
C:Inetpubwwwrootstudentigrupeabcdnote.html
Modalitatea de a vedea
datele ca parte a folderului radacina din serverul web este foarte
utila. Chiar daca in realitate datele rezida pe un disc diferit,
pentru managementul spatiului, sau chiar pe o masina
diferita. Folderele virtuale reprezinta rezolvarea dilemei de mai
sus, prin aparitia logica a unui folder din afara directorului
radacina a serverului web ca parte din el.
De exemplu, un site
care tine anunturile locale intr-un folder la
E:StiriLocale
iar serverul web are radacina in
C:Inetpubwwwroot
Administratorul serverului Web poate sa defineasca un folder
virtual numit /stiri care sa reprezinte calea E:StiriLocale. Cand
serverul Web receptioneaza cererea
GET /stiri/default.html
el va cauta si va trimite catre browser fisierul
E:StiriLocaledefault.html
si nu
C:Inetpubwwwrootstiridefault.html
Un motiv pentru
crearea de foldere virtuale este securitatea. Multe servere web utilizeaza
folderele virtuale pentru a implementa permisii de acces la nivel de folder.
Procesarea
unei interogari de la client
In cele ce
urmeaza vom considera o secventa completa de pasi executati
de serverul web pentru procesarea unei interogari receptionate de la
clientul web:
browserul web sau alt client web trimite
catre serverul web o interogare, cerand anumite resurse. Aceasta
interogare este transmisa in format HTTP, in timp ce adresa resursei
cerute este specificata in format Uniform Resource Locator (URL).
Interogarile sunt facute de obicei utilizind comanda HTTP Get.
dupa receptionarea interogarii
de la client, serverul web determina existenta resursei in cadrul
resurselor controlate de serverul respectiv;
in cazul in care resursa este
disponibila, serverul web determina drepturile de acces, iar
daca aceste drepturi nu au fost incalcate, returneaza catre
client continutul resursei dorite;
in cazul in care drepturile de acces au fost
incalcate, serverul web respinge interogarea, returnand clientului
atentionarea de rigoare;
in cazul in care resurse nu se
gaseste pe serverul web, serverul determina informatia
despre resursa din fisierele de configuratie, acestea cuprinzand
inclusiv o posibila relocare in retea. Daca resursa a fost
alocata serverului, dar a fost redirectata temporar catre o
alta locatie, serverul informeaza clientul despre acest fapt;
daca serverul web suporta un arbore
virtual construit din alte servere web, cautarea va fi
redirectionata catre resursele necesare;
daca serverul web este utilizat ca
si server proxy, el actioneaza pe de-o parte ca si server
web pentru clientul care a transmis interogarea, iar pe de alta parte ca
si client web pentru a interoga un alt server web. Acesta este un simplu
agent de retransmisie care regaseste si stocheaza in cache
pagini web pentru persoanele din interior dar care nu permite accesul
vizitatorilor la resursele interne. Pentru a utiliza un server proxy, fiecare
browser trebuie configurat sa poata:
a. trimite toate cererile GET catre serverul
proxy si nu catre gazda specificata in URL;
b. sa includa intregul URL, inclusiv
numele serverului si portul in cererea GET.
dupa returnarea informatiilor
catre client, serverul inchide conexiune cu acesta.

Figura : Interactiunile dintre client si
server.

Figura : Server web pe post de agent de retransmisie
(proxy).
In cazul in care resursa obtinuta de la
server este un fisier HTML, browserul, prin examinarea marcajului, poate
determina cereri pentru alte fisiere. In acest caz, browser-ul le
regaseste prin alte comenzi GET. Serverul web trateaza toate
cererile GET in mod identic, indiferent de tipul fisierului. Sarcina de
asamblare a fisierelor regasite si formatarea paginii revine
browser-ului in intregime.
In mod normal, browser-ele mai trimit pe langa
cererea GET si diferite anteturi care includ informatii
aditionale despre conexiune. In cererea urmatoare, de exemplu,
browser-ul indica ce fel de fisiere poate sa accepte, ce
limba prefera (engleza), marimea si adancimea de
culoare pentru ecranul vizitatorului, sistemul de operare al vizitatorului
si tipul de procesor, numele si versiunea de browser, numele
calculatorului pe care vizitatorul incearca sa-l acceseze si un
indicator prin care browser-ul arata ca doreste sa
utilizeze aceeasi conexiune pentru mai multe transferuri si nu
sa deschida o noua conexiune pentru fiecare fisier:
GET / HTTP/1.1
Accept: image/gif, image/x-xbitmap, image/jpeg, image/jpg, */*
Accept-Language: en
UA-pixels: 1024x768
UA-color: color16
UA-OS: Windows 2000
UA-CPU: x86
Visitor-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows 2000)
Host: econ.unitbv.ro
Connection: Keep-Alive
In raspuns la
aceasta cerere, serverul raspunde cu un antet pentru fiecare
pagina in care sunt indicate: un cod de stare (200 OK, numele si
versiunea serverului web, dorinta de a reutiliza conexiunea, data si
ora, tipul fisierului (text/html), posibilitatea de a oferi o
portiune de bytes a unei pagini, data ultimei modificari a paginii
returnate si lungimea paginii returnate in bytes.
HTTP/1.0 200 OK
Server: Microsoft-IIS/6.0
Connection: keep-alive
Date: Sat, 19 Oct 2002 22:41:10 GMT
Content-Type: text/html
Accept-Ranges: bytes
Last-Modified: Mon, 05 Nov 2002 03:50:15 GMT
Content-Length: 5574
Paginile web ce
contin formulare utilizeaza si al doilea tip de cerere
numita POST. Metoda POST utilizeaza anteturi HTTP aditionale
pentru a transmite numele si valorile campurilor dintr-un formular, oferind
in acest fel o mai mare flexibilitate si capacitate de manipulare a
datelor decat utilizarea metodei GET impreuna cu query string.
Explicarea
completa a anteturilor HTTP nu constituie scopul acestei lucrari, dar
autorii de pagini web trebuie sa fie constienti de faptul
ca browser-ele si serverele web schimba intre ele o varietate de
informatii despre ele insele. De exemplu, informatiile oferite de
browser-e pot fi utilizate de servere pentru a raspunde in mod diferit de
la browser la browser.
Serverele web moderne pot fi utilizate pentru
rezolvarea unei clase mai largi de probleme, intre care enumeram:
suport pentru o baza de date de documente
ierarhice, procesarea interogarilor si controlul accesului la
informatii pentru programele client-side;
pre-procesarea datelor inainte de a
raspunde interogarii;
interactiune cu alte programe externet
si alte servere (motoare de cautare, de exemplu).
HTTPS. Secure Sockets Layer
Securitatea este
intotdeauna o problema pe Web, mai ales pentru activitatile care
necesita transfer de bani, schimb de numere de carti de credit,
numere de conturi bancare sau alte tranzactii financiare. In aceste
cazuri, ambele parti ale unei astfel de tranzactii doresc
criptarea informatiilor astfel incat nimeni sa nu poata
interveni in comunicatie sa modifice sau sa duplice
tranzactia, sau sa captureze datele pentru uz fraudulos.
Secure Sockets Layer
(SSL) ofera un astfel de criptare pentru Web. SSL este utilizat in felul
urmator:
vizitatorul Web trimite un URL avand ca
protocol de identificare https;
browser-ul contacteaza serverul Web pe
portul 443 (portul 80 este implicit pentru trafic normal);
browser-ul si serverul negociaza o
cheie de criptare pentru sesiunea curenta. Aceasta cheie cuprinde
factori specifici pentru calculatorul vizitatorului, precum adresa IP,
facand putin probabil faptul ca alt calculator sa ghiceasca
sau sa obtina cheia respectiva;
dupa stabilirea cheii de criptare, toate
comunicatiile, inclusiv URL-urile https sunt criptate cu cheia
respectiva, dupa care:
a. browser-ul trimite datele criptate catre
serviciul SSL pe portul 443;
b. serviciul SSL decripteaza transmisia
si o inainteaza, intern, catre serverul si portul cerut;
c. serverul SSL primeste raspunsul
serverului Web, il cripteaza si il transmite catre browser;
d. browser-ul face decriptarea si
afiseaza rezultatele;

Figura : Interactiunea intre client si
server prin SSL.
Browser-ele sau clientii in general, pot sa
initieze intotdeauna o conexiune SSL, dar pentru ca aceasta sa
functioneze, serverul web trebuie sa fie corect configurat in ceea ce
priveste conexiunile criptate.
HTTP - protocol fara stare
Cea mai mare limitate
a HTTP este faptul ca nu are stare. Acest lucru semnifica faptul
ca o conexiune este inchisa imediat dupa ce este transmisa
o pagina, iar serverul nu retine informatii folositoare despre
acest lucru. Acest fapt devine de-a dreptul suparator cand o
singura tranzactie necesita cateva pagini Web pentru a fi
finalizata. Presupunand ca un vizitator aduce pe ecran prima
pagina Web, transmite anumite informatii si apoi el obtine
al doilea ecran pentru introducerea altor date. Cand vizitatorul trimite cea
de-a doua pagina, serverul nu mai stie ce date s-au trimis in prima
pagina.
Pentru aceasta
dilema exista trei solutii:
serverul
trebuie sa scrie toate datele referitoare la o tranzactie pe fiecare
pagina web, iar browser-ul sa le transmita inapoi cu fiecare
tranzactie. Acest lucru presupune utilizarea de campuri ascunse de tip
formular pentru fiecare articol;
serverul
si browser-ul sa schimbe date referitoare la tranzactii sub
forma de cookie-uri. Cookie-urile sunt campuri de date pe care browser-ele
si serverele le schimba intre ele prin intermediul anteturilor HTTP
speciale. Cookie-urile pot fi aplicate unei pagini sau unui site, dar
cookie-urile dintr-un site nu pot fi vazute de altul;
serverul
Web sa mentina datele tranzactiei intr-un fisier sau
baza de date special conceputa pentru acest lucru. Pentru
regasirea datelor se transmite un identificator de tranzactie
catre si de la server prin campuri ascunse, query string sau
cookie-uri.
In mod implicit cookie-urile rezida in memoria
browser-ului si sunt sterse in momentul in care vizitatorul il
inchide. Cu toate acestea, o pagina web poate preciza faptul ca un cookie
sa fie salvat in mod persistent, intr-un fisier special de pe discul
vizitatorului. Cat timp cookie-ul exista pentru o anumita pagina
Web, folder sau site, browser-ul il transmite catre server odata cu
fiecare cerere, pana la expirarea cookie-ului. Serverul specifica de
fiecare data o data de expirare pentru acel cookie.
Server HTTP virtuale
Contrar credintei
potrivit careia toate site-urile incep cu www si se termina
intr-un nume de domeniu principal, nu exista nici o lege specifica
pentru aceasta. Cu toate acestea, vizitatorii asteapta acest lucru,
creand probleme atat pentru site-urile mari cat si pentru cele mai mici.
Pentru site-urile Web
mari, problema apare in momentul in care se doreste construirea de servere
suficient de puternice ca sa raspunda la sute sau mii de cereri
pe secunda. Solutia este upgrade-ul software si hardware sau
setarea de servere aditionale pentru diferite nivele ale meniurilor din
paginile web. Exista, de asemenea, si sisteme care sa distribuie
in mod aleator cererile primite catre unul sau mai multe servere
configurate in mod identic, chiar daca cererile specifica
aceeasi adresa IP.
Pentru site-urile web
mici, problema este costul construirii serverelor web separate, chiar daca
numarul de vizitatori pe zi este mic sau moderat. Solutia normala
este instalarea mai multor site-uri web pe aceeasi masina
server, chiar daca proprietarii de site-uri doresc nume precum www.<nume-site>.ro sau www.<nume-site>.com in loc de www.<provider>.ro/<nume-site>
Serverele virtuale
ofera o solutie eleganta la aceasta problema. Un
administrator seteaza nume DNS si adrese IP diferite pentru fiecare
site Web, configurand software-ul de retea al masinii sa
raspunda la mai multe astfel de adrese. In cele din urma
administratorul configureaza serverul web sa acceseze foldere
radacina diferite, in functie de adresa IP specificata
de cererea vizitatorului. In acest fel site-uri cu nume precum www.<nume-site>.ro sau www.<nume-site>.com pot accesa foldere radacina
diferite in aceeasi masina fizica.
Pentru a se asigura
faptul ca fiecare utilizator va atinge destinatia dorita, pentru
fiecare site trebuie configurata o identitate unica. Deci, fiecare
site web trebuie distins de altul prin cel putin una din
modalitatile unice de identificare: un nume pentru antetul gazdei, o
adresa IP sau un numar de port TCP.
|
Identificator site web
|
Utilizare
|
|
Nume pentru antet
(host header)
|
Recomandata pentru cele mai multe situatii. Prin setarea de
anteturi diferite pentru fiecare site, se poate utiliza o adresa IP
unica si acelasi port pentru mai multe servere virtuale;
|
|
Adresa IP unica
|
Utilizata in principal pentru serviciile Web care necesita
utilizare HTTPS (Secure Socket Layer) pe serverul local;
|
|
Port TCP nestandard
|
Nu este in general recomandata
utilizarea de porturi TCP nestandard, deoarece conexiunile
(majoritatii) utilizatorilor sunt blocate prin intermediul
firewall-urilor. Porturile nestandard pot fi folosite atat pentru dezvoltarea
de site-uri Web private cat si pentru testarea, dar mai putin
pentru productie.
|
Tabelul : Modalitati de
identificare a site-urilor web.
Prin schimbarea unuia
din acesti identificatori se pot crea identitati unice pentru
site-uri web multiple fara instalarea unui server dedicat pentru
fiecare site. De asemenea, se poate specifica un director
radacina pentru fiecare site in parte, atat pe serverul local
cat si pe resurse partajate din retea.
Standardizarea unei
metode pentru identificarea unica a unui site web la nivel de server
(masina) este de preferinta facuta prin intermediul
anteturilor unice. Utilizarea unei metode unice standard per server
imbunatateste performanta prin optimizarea cache-ului
si a cautarii rutelor pentru adresare. Utilizarea oricarei
combinatii de anteturi, adrese unice IP si porturi nestandard conduce
la degradarea performantei tuturor site-urilor web de pe un server.
Consolidarea
site-urilor web are ca avantaje economisirea resurselor hardware, conservarea
spatiului si reducerea costurilor pentru energie.
O scurta trecere in revista a
programarii la nivel de server web
Trimiterea de pagini
gata create catre client este o functie utila, dar generarea de
pagini dinamice, "din zbor" ofera o flexibilitate considerabil mai mare.
Generarea de pagini cu continut dinamic necesita programare, dar inseamna
si faptul ca acelasi URL poate produce rezultate diferite, in
functie de data, ora, tipul browser-ului, interactiunea cu
utilizatorul sau orice alte informatii disponibile pe serverul de web.
Aceeasi tehnologie este utilizata pentru a procesa intrarile din
formulare (datele care sunt trimise pe server) si pentru a afisa
datele din bazele de date.
Majoritatea serverelor
HTTP ofera si facilitati de programare server-side care
precum facilitati de cautare in text sau procesarea datelor
trimise pe server prin intermediul formularelor.
In continuare,
enumeram cateva dintre cele mai populare modalitati de creare de
pagini cu continut dinamic:
Common
Gateway Interface (CGI);
Internet
Server Application Programming Interface (ISAPI);
Active
Server Pages (ASP);
ASP.NET;
Java
Server Pages;
PHP;
Perl;
Common Gateway Interface (CGI) - in momentul in care
un vizitator al unei pagini utilizeaza un hyperlink, URL asociat nu
identifica un fisier de pe server care trebuie transmis catre
browser ci un program pe care trebuie sa-l execute serverul de web. Aceste
programe primesc, de obicei, date de intrare din formularele HTML sau datele
adaugate la sfarsitul unui URL si genereaza HTML care va fi
trimis catre browser pentru afisare. Prin intermediul acestor
programe care se executa pe server se pot actualiza baze de date de pe
server, se pot trimite mesaje e-mail sau se pot executa alte actiuni
necesare;
Internet Server Application Programming Interface
(ISAPI) - aceasta modalitate de creare de pagini HTML dinamice este similara
CGI in ceea ce priveste functiile indeplinite, dar este
implementata in mod diferit. Astfel, programele ISAPI sunt biblioteci cu
incarcare dinamica (DLL) pe care sistemul de operare trebuie sa
le incarce numai o singura data, pentru orice numar de executii.
In contrast, aplicatiile CGI sunt fisiere executabile (EXE) care
trebuie incarcate, initializate, executate si descarcate
din memorie la fiecare cerere. Pentru executia unei aplicatii de tip
ISAPI, vizitatorul va trimite catre server o cerere sub forma unui URL ce
contine numele unei biblioteci cu incarcare dinamica;
Active Server Pages (ASP) - spre deosebire de CGI
si ISAPI, paginile ASP constau din cod HTML amestecat cu codul unui limbaj
de programare. Serverul Web interpreteaza si executa codul programului
si trimite catre browser rezultatul acestei executii. Pagina web
care contine script la nivel de server (server-side) si este
creata prin aceasta modalitate are extensia .asp. Programatorii
utilizeaza de obicei pentru paginile ASP cod creat utilizand limbajul
Microsoft VBScript si JavaScript. Aceste limbaje pot invoca servicii
integrate in functiile serverului web, controale ActiveX, applet-uri Java
sau alte obiecte.
ASP.NET - paginile ASP.NET constau din programe scrise
in diferite limbaje de programare care se executa la nivel de server web,
impreuna cu un set de controale ASP.NET la nivel de server si
controale HTML care pot fi controlate la nivel de server. Diferenta
esentiala fata de versiunea anterioara (ASP)
consta in compilarea paginii in momentul primei executii (pagina
poate fi compilata si anterior executiei), ducand astfel la o
performanta deosebita in comparatie cu scripturile ASP.
Procesarea distribuita a informatiilor pe baza
programelor mobile
Una din
facilitatile cheie ale arhitecturii Internet este distribuirea
procesarii informatiei pe baza programelor mobile. Programele de
navigare web, executate la nivel de statie de lucru, pot nu numai sa
vizualizeze pagini web si sa execute tranzitia catre alte
resurse, dar pot si sa activeze programe la nivel de server, sa
le interpreteze si sa le lanseze in executie, dupa cum cere
documentul web care este deschis. Aceste programe sunt transferate
impreuna cu documentul web curent de pe serverul web. Acest tip de
procesare distribuita a informatiilor asigura concentrarea
intregului sistem al aplicatiei la nivel de server web.
Exista trei
tipuri mari de programe care pot fi asociate unui document web si
transferate catre o statie de lucru in vederea executiei:
Applet-uri Java, pregatite si executate
de tehnologia Java;
Programe scrise in diverse limbaje de
scripting (JavaScript, VBScript, VRML, etc);
Componente ActiveX, legate de tehnologia
ActiveX.
Faptul ca exista o astfel de varietate de
programe mobile poate fi explicata atat prin capacitatile
si functionalitatile diferite cat si prin
competitia dintre marile companii dezvoltatoare de aplicatii (Sun
Microsystems, Microsoft, Macromedia etc.).
Tehnologia
Java
Java a fost
creata de Sun Microsystems la inceputul anilor 1990, ca raspuns la
cererea acuta de programe orientate inspre utilizare in mediul de
retea si integrate cu tehnologia Web. Forta conducatoare
din spatele tehnologiei Java consta in combinarea cererii de mobilitate
si independenta de hardware si sisteme de operare, cu
siguranta si eficienta procesarii informatiei. Ca
rezultat, a fost dezvoltat limbajul Java, iar tehnologia integrata care
presupune crearea si utilizarea de programe mobile este cunoscuta sub
denumirea de tehnologie Java.
Java este un limbaj de
programare simplu, orientat-obiect, construit pe baza limbajului C++, din care
au fost eliminate unele facilitati care nu au fost considerate
necesare, in timp ce au fost adaugate altele, care sa ofere
siguranta si eficienta pentru calcula distribuit.
Multe din aceste facilitati au fost imprumutate din limbajele
Objective C si Smalltalk. Atat dezvoltarea modulara a programelor,
implementata in limbaj cat si simplitatea insasi a
limbajului permit nu numai dezvoltarea rapida de noi programe, ci si
actualizarea aplicatiilor scrise si testate anterior in Java. Pe
langa elementele standard de limbaj, Java cuprinde o serie de biblioteci
utile, din care se pot construi aplicatii de orice complexitate. De
asemenea, setul standard de biblioteci poate fi oricand suplimentat cu
functii noi importante.
Programele Java create
pentru executia pe statii de lucru in mediul de executie al unui
browser web sunt numite applet-uri Java, sau applet-uri. In
concordanta cu natura sa proprie, fiecare applet reprezinta un
mic program in care trebuie specificate anumite functii in mod
obligatoriu. Applet-ul este incarcat de pe server prin retea si
executat in mediul de lucru al browser-lui, conform figurii urmatoare.
Applet-urile nu sunt cuprinse in documentele web, ci sunt stocate in
fisiere separate pe server, fiind descarcate numai daca
documentele web au specificate tag-uri speciale pentru acest lucru (tag-ul <APPLET>

Figura : Transferul si executia
applet-urilor Java.
Independenta
byte-code a Java de platforme hardware si software este posibila prin
implementarea unei aplicatii numite "procesor virtual Java", creat pentru
interpretarea applet-urilor pe fiecare din aceste platforme.
Programele de tip Java
byte-code au urmatoarele facilitati:
acestea pot fi interpretate si compilate
"on the fly" sau "din zbor", direct in cod-masina pentru orice
platforma hardware existenta;
marimea comenzii din byte-code este
redusa la minimum prin reducerea complexitatii si
marimii applet-urilor Java, in comparatie cu orice alte programe;
fiecare byte-code al programelor contine
informatii complete despre program, permitand testarea in vederea
sigurantei executiei.
Compilarea "din zbor", cunoscuta si sub
numele de compilare dinamica, se refera la conversia applet-urilor
Java in codul masina nativ de executie al statiei de lucru,
chiar inainte de executie. Dupa conversie, aceste programe pot fi
executate ca si programe native. Aceasta compilare dinamica
utilizeaza un compilator specializat in locul unei masini virtuale,
accelerand viteza de executie a applet-urilor. Cu toate acestea, sunt
pierdute anumite masuri luate pentru siguranta procesarii
informatiilor, de aceea compilarea dinamica a applet-urilor Java in
interiorul browser-elor web nu se practica.
Nu numai applet-urile,
adica aplicatiile mobile, pot fi scrise in limbajul Java, ci si
aplicatii statice. Pentru a obtine un nivel mai inalt de
performanta, codul sursa al programelor se compileaza nu in
byet-code, ci in cod dependent de masina, care permite executia
directa de catre procesor.
Astazi
exista o multime de instrumente de dezvoltare pentru crearea atat a
applet-urilor Java, cat si a aplicatiilor Java. Printre acestea se numara Microsoft
Visual J++, Borland Jbuilder, Sun Microsystems Java Workshop etc.
Tehnologii
bazate pe utilizarea limbajelor de scripting
Tehnologiile pentru
dezvoltarea programelor mobile bazate pe utilizarea limbajelor de scripting au
aparut si s-au dezvoltat in paralel cu tehnologia Java. Cea mai
importanta diferenta intre tehnologiile sau limbajele de scripting
si Java este interpretarea comanda-cu-comanda a sursei
programelor de scripting, ceea ce nu face necesara compilarea in
byte-code, in vederea executiei. In acest caz, functia de
interpretare a codului este realizata de catre browser-ul web.
Natura limbajelor de
scripting, numite de asemenea si macro-limbaje, faciliteaza depanarea
si dezvoltarea programelor scrise cu ele. Printre principalele limbaje de
scripting create in vederea dezvoltarii de programe mobile se numara:
JavaScript, dezvoltate in colaborare de
Netscape si Sun Microsystems;
VBScript, dezvoltat de Microsoft pentru
utilizarea in Internet Explorer;
Virtual Reality Modeling Language (VRML),
dezvoltat de Silicon Graphics;
Flash ActionScript, realizat de Macromedia
pentru realizarea interactivitatii cu obiectele Flash.
JavaScript a fost dezvoltat initial de Netscape
si a aparut pentru prima data in browser-ul web Netscape
Navigator 2.0 sub denumirea de LiveScript. Dupa inceperea colaborarii
cuSun Microsystem si apropierea sau trecerea sub influenta Java,
limbajul s-a numit JavaScript. JavaScript nu este un limbaj derivat din Java
si, cu toate ca au in comun unele atribute, ele pot fi numite doar
rude indepartate. O comparatie intre Java si JavaScript se poate
observa si in tabelul urmator:
|
Java
|
JavaScript
|
|
Programul trebuie compilat in byte-code
pentru a se putea executa la nivelde client
|
Programul este interpretat la nivel de
client in forma initiala, bazata pe text
|
|
Este orientat obiect. Applet-urile constau
din obiecte descrise cu ajutorul claselor si mostenirii
|
Bazat pe obiecte. Nu exista clase
pentru mecanismul de mostenire
|
|
Applet-urile sunt apelate de catre
paginile web, dar sunt stocate separat de acestea, in fisiere
individuale
|
Programele sunt apelate de catre
paginile web si pot fi construite atat direct in documentele web cat
si separat de acestea
|
|
Toate tipurile de date si variabilele
trebuie declarate inainte de utilizare
|
Tipurile de date si variabilele nu
trebuie declarate
|
|
Legare statica. Legaturile dintre
obiecte trebuie sa existe in momentul compilarii
|
Legare dinamica. Legaturile
dintre obiecte sunt verificate in timpul executiei
|
|
Applet-urile nu pot scrie pe disc sau
executa functii sistem
|
Applet-urile nu
pot scrie pe disc sau executa functii sistem
|
Tabelul : Comparatie intre Java
si JavaScript.
JavaScript este un
limbaj simplificat, interpretat, bazat pe functii orientate-obiect.
Simplitatea i se datoreaza lipsei rigiditatii arhitecturii de
tipuri si a semanticii. Natura orientata-obiect se manifesta
prin abilitatea de a opera cu fereastra browser-ului, cu bara de stare sau cu
alte unitati ale interfetei browser-ului web sau cu alte obiecte
din ierarhie. JavaScript nu este atat de bogat ca si limbajul Java, dar
este mult mai usor si mai eficient in realizarea unor sarcini legate
de procesarea documentelor Web sau pentru interactiunea cu utilizatorul in
momentul vizualizarii paginilor. Avand o multime de functii la
dispozitie, JavaScript poate lucra cu ferestre de dialog, executa calcule
matematice, produce noi documente, gestiona apasarea pe butoanele din
ferestre etc. Iar tot cu ajutorul JavaScript se pot seta o serie de atribute
si proprietati ale modulelor (plug-in-urilor) care sunt
utilizate de catre browser-ul web.
Comenzile JavaScript
sunt scrise direct in pagina web si sunt executate de catre browser
in timpul incarcarii acesteia sau in timpul operatiilor
specifice executate de utilizator in timpul interactiunii cu pagina web
(de exemplu, apasarea unui obiect din pagina, pozitionarea
cursorului de mouse pe un anumit obiect sau introducerea de date in formulare).
La fel ca si in orice alt limbaj, siguranta procesarii
informatiilor este prioritara. JavaScript, desi nu este
considerat a fi un limbaj cu un grad inalt de securitate, intruneste cele
mai multe cerinte prin ne-includerea in limbaj a unor functii care ar
fi dus la vulnerabilitati. La fel ca si applet-urile Java,
programele scrise cu JavaScript nu pot executa operatiuni cu fisiere
si nu suporta functii de retea. Un program scris in JavaScript
nu poate, de exemplu, sa deschida un port TCP/IP si este capabil
numai sa incarce obiectele la adresele indicate si sa formeze
datele care vor fi transferate catre server. Browser-ele moderne permit
utilizatorilor sa seteze diferite niveluri de securitate, astfel incat
programele scrise in JavaScript sa se concentreze numai asupra unui
interval ingust de informatii.
JavaScript si-a
cistigat popularitatea prin faptul ca programele se pot dezvolta
rapid, acestea sunt mici si ofera acces simplificat la functiile
oferite de catre browser-ul web. Principalul dezavantaj al JavaScript este
rata mica de executie, datorata naturii interpretate a
limbajului.
Trebuie sa
notam faptul ca Netscape si Microsoft au implementat JavaScript
in mod diferit, aceste discrepante putand avea ca rezultat
incompatibilitatea utilizarii programelor realizate pentru Nescape in
Internet Explorer si invers. Pentru a elimina aceste neplaceri, este
necesar sa se verifice facilitatile oferite de diverse programe
de tip browser web.
VBScript (Visual Basic
Script) este similar cu Java in multe privinte. VBScript este un subset al
Visual Basic, fiind de asemenea orientat pentru programarea paginilor web la
nivel de client. Cu VBScript se pot utiliza obiecte diverse, inclusiv obiecte
scrise in alte limbaje.
Tehnologiile
ActiveX
ActiveX
reprezinta un set de tehnologii de la Microsoft care se concentreaza
asupra integrarii si unificarii metodelor de reprezentare
si procesare a informatiilor din retele de calculatoare,
construite in concordanta cu arhitectura web. Ideea principala a
tehnologiei ActiveX consta in mijloacele identice de a accesa
informatii din retea, in care tehnologia web a fost selectata ca
baza pentru unificarea acestor mijloace de acces.
Potrivit filosofiei ActiveX, browser-ul web ar trebui
sa devina parte integranta a sistemului de operare. Mai mult,
metodele de obtinere a accesului la orice informatii din calculator,
de pe serverul local, din reteaua locala sau din Internet, ar trebui
sa fie absolut identice si transparente pentru utilizator. Acest
concept a fost implementat in browser-ul Microsoft Internet Explorer inca
de la versiunea 4.

Figura : Acces uniform la resursele din retea.
Din punct de vedere al
mobilitatii programelor, tehnologiile ActiveX reprezinta o
alternativa la tehnologiile Java si JavaScript, fiind in acelasi
timp si o modalitate de suplimentare a acestora din urma. ActiveX
ofera nu numai posibilitatea dezvoltarii si executiei de
programe mobile, ci implementeaza si un numar de
posibilitati alternative, facand posibila, de exemplu,
apelarea unor functii pentru vizualizarea si editarea documentelor
Word, Excel, PowerPoint direct din mediul de lucru al browser-ului.
ActiveX suporta urmatoarele tipuri de
programe mobile, programe care pot fi atasate documentelor web si
transmise catre statiile de lucru pentru executie:
Controale ActiveX;
Applet-uri Java;
Programe scrise in limbaje de scripting precum
JavaScript, VBScript sau VRML.
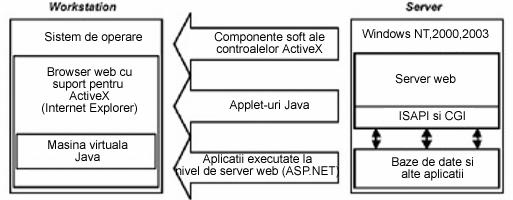
Figura : Migrarea programelor prin utilizarea
tehnologiei ActiveX.
Controalele ActiveX
reprezinta de fapt programe executabile care pot fi incarcate de pe
server pentru executie la nivelul statiei de lucru. La fel ca si
applet-urile Java, ele nu sunt incluse direct in documentul web, ci exista
in fisiere separate.
Controalele ActiveX difera de applet-urile Java
astfel:
Controalele ActiveX contin cod executabil
care depinde de platforma hardware si de sistemul de operare, in timp ce
applet-urile Java constau din cod independent de masina;
Unitatile ActiveX incarcate la
nivel de client raman in sistemul client, in timp ce applet-urile Java
trebuie incarcate la fiecare cerere;
Deoarece controalele ActiveX nu
functioneaza la fel ca si applet-urile Java, sub controlul unui manager
de securitate, acestea pot obtine acces la fisierele de statia
client si pot executa functii tipice pentru aplicatiile
conventionale.
Componentele ActiveX, la fel ca si
aplicatiile scrise in JavaScript si VBScript, pot contine
apeluri catre functii ActiveX in vederea oferirii unui numar de
servicii, printre care:
Crearea de efecte multimedia de inalta
calitate;
Deschiderea si editarea documentelor
electronice, prin apelarea aplicatiilor care suporta standardul
Object Linking and Embedding (OLE). Un exemplu poate fi editarea documentelor
Microsoft Office direct in browser;
Access la sistemul de operare, in vederea
optimizarii parametrilor de executie a programelor obtinute de
la server.
Programele scrise in macro-limbajele JavaScript
si VBScript pot automatiza interactiunea dintre multe obiecte, intre
care applet-uri Java, componente ActiveX si alte programe instalate la
nivelul statiei de lucru client, permitand lucrul sub forma unui
spatiu de lucru web integrat.
Dynamic HTML
Dynamic HTML (DHTML) este
doar HTML simplu in care au fost adaugate citeva elemente impreuna cu
modalitatea de acces la ele prin intermediul limbajelor de scripting. Noile
elemente permit control precis al layout-ului paginii, in timp ce noul model
obiectual permite manipularea acestor elemente prin intermediul scripturilor
client/server si server/side.
Deoarece HTML a fost
creat pentru layout-uri "curgatoare", nu exista control asupra
modalitatii de asezare a texului si a imaginilor si
inainte ca paginile sa fie vizualizate pe o multime de platforme
si masini diferite, care sa aiba ecrane si fonturi de
tipuri diferite.
Mai tarziu au fost
adaugate tag-urile <table> si <font> care au permis un
control mai riguros asupra asezarii in pagina si a
stilurilor de afisare, dar si acestea au limitarile lor. Chiar
si JavaScript, care permite manipularea prin programare a elementelor
paginii, precum imagini sau a campurilor din formulare, are anumite
limitari.
DHTML a adaugat
elemente care permit controlul precis al layout-ului paginii:
foile de stiluri: permit definirea de stiluri
diferite pentru prezentarea texului, precum culori, marimea marginilor,
fonturi etc;
pozitionarea continutului: permite
determinarea cu exactitate a pozitionarii elementelor de
continut in fereastra browser-ului. Elementele se pot suprapune, pot fi
ascunse sau pot fi mutate in mod dinamic;
fonturi descarcabile: presupun ca va
fi utilizat fontul care este ales pentru text, chiar daca fontul nu este
disponibil pe masina client.
Document Object Model (DOM) defineste atat
proprietatile diferitelor elemente ale paginii, cat si metodele
de utilizare pentru modificarea acestora, prin utilizarea limbajelor de
scripting putandu-se modifica in mod dinamic continutul paginii (de
exemplu pot fi aplicate diferite schimbari in functie de tipul de
browser utilizat sau in functie de actiunile utilizatorului).
Trebuie sa
notam faptul ca toate companiile producatoare de software de
navigare pe Internet ofera suport pentru DHTML, dar acesta difera de
la browser la browser.
Motoare de cautare
Vestea buna
despre Internet si despre componenta sa vizibila, World Wide Web-ul,
este ca exista miliarde de pagini disponibile, pagini care
asteapta sa fie vizitate pentru a oferi informatii despre o
miriada de subiecte. Ceea ce este mai putin bun este ca
exista milioane de pagini disponibile, cele mai multe dintre ele denumite
in functie de dorinta autorului, toate pe servere cu nume criptice
sau protejate. Totusi, in momentul in care un utilizator doreste sa
acceseze un anumit subiect, acesta utilizeaza un motor de cautare pe
Internet.
Motoarele de
cautare pe Internet sunt site-uri web specializate, create pentru a ajuta
oamenii sa gaseasca informatii stocate in alte site-uri.
Exista multe diferente in modul in care lucreaza diferitele
motoare de cautare, dar acestea executa in general aceleasi trei
sarcini de baza:
cauta pe Internet sau "selecteaza"
parti din Internet, pe baza cuvintelor importante;
retin un index al cuvintelor pe care le
gasesc si a locului acestora;
permit utilizatorilor sa caute cuvinte
sau combinatii de cuvinte gasite in acest index.
Motoarele de cautare initiale detineau
un index cu cateva sute de mii de pagini si documente, si
receptionau si serveau cam doua mii de cereri pe zi.
Astazi, un motor de cautare de varf indexeaza sute de milioane
sau chiar miliarde de pagini si raspunde la zeci de milioane de
interogari pe zi. In continuare vom vedea modalitatea in care sunt
executate aceste sarcini si cum motoarele de cautare de pe Internet
alatura date separate pentru ca utilizatorul sa
gaseasca ceea ce are nevoie.
Cand se vorbeste despre motoare de cautare
pe Internet, se vorbeste in general despre motoare de cautare pe
World Wide Web. Totusi, inainte ca web-ul sa devina partea
proeminenta a Internetului, existau si alt fel de motoare de
cautare, care permiteau utilizatorilor sa gaseasca
informatii in Internet. Astfel, exista si astazi, dar se
utilizeaza foarte putin, programe precum "gopher" sau "Archie", care
tineau indexuri de fisiere stocate pe serverele conectate le Internet,
reducand in mod semnificativ timpul necesar gasirii programelor sau
documentelor. La sfarsitul anilor 1980, utilizarea la maximum a
Internetului insemna utilizarea programelor "gopher", "Archie", "Veronica" etc.
Astazi cei mai multi utilizatori isi limiteaza
cautarile la serverele web, ftp sau de grupuri de dialog.
Inainte ca un motor de cautare sa poate
spuna utilizatorilor unde se gasesc anumite documente, acestea
trebuie sa fie mai intai gasite. Pentru a gasi informatii
din miliardele de pagini web, un motor de cautare foloseste o
aplicatie speciala, numita "robot de cautare" sau "spider",
pentru a construi o lista de cuvinte gasite in paginile web. Procesul
prin care un spider isi construieste lista se numeste "web
crawling", iar pentru ca un motor de cautare/spider sa
construiasca o lista eficienta de cuvinte, acesta trebuie
sa caute printr-o multime de pagini.

Figura : Un 'Spider' obtine
continutul unei pagini web si creeaza o lista de cuvinte
cheie care permit utilizatorilor sa gaseasca informatiile
pe care le doresc.
Un spider isi incepe cautarea prin web
pornind de obicei de la o lista cu servere intens utilizate si cu
pagini web foarte populare. Spider-ul va incepe cu un site popular, indexand
cuvintele din pagini si urmand toate legaturile gasite in site-ul
respectiv, ajungand in acest fel sa traverseze si sa indexeze
partea cea mai utilizata a web-ului.
Google.com a inceput
ca un motor de cautare academic. In lucrarea care descrie modalitatea de
construire a acestuia, Sergey Brin si Lawrence Page au exemplificat cat de
repede poate sa lucreze un spider. Astfel, sistemul a fost construit
pentru a utiliza mai multi spider-i, trei de obicei, fiecare spider putand
sa tina deschise 300 de conexiuni catre pagini web la un
moment dat. La cea mai ridicata performanta, folosind patru
spider-i, sistemul putea cauta in peste 100 pagini pe secunda,
generand 600 kilobytes de date in fiecare secunda.
Mentinerea unui
sistem rapid insemna de asemenea construirea unui sistem care sa
alimenteze spider-ii cu informatii. Astfel, Google.com initial avea un
server dedicat pentru a oferi URL-uri spider-ilor. Google avea de asemenea
si propriul server DNS, translatarea numelor in adrese fiind semnificativ
mai rapida, micsorand in acelasi timp si intarzierile
datorate retelelor.
In momentul in care un
spider Google vizita o pagina HTML, acesta tinea cont de doua
lucruri:
cuvintele gasite in pagina;
pozitia acestor cuvinte in pagina.
Cuvintele gasite
in titlu, subtitlu, metatag-uri si alte pozitii de
importanta relativa erau notate cu o semnificatie
speciala in timpul cautarilor initiate de utilizatori. De
asemenea, spider-ul a fost construit pentru a indexa toate cuvintele
semnificative din pagina, lasand la o parte cuvintele de
legatura.
Alti spider-i
folosesc alte procedee pentru indexare, permitand, spre exemplu,
spider-ilor sa opereze mai rapid sau sa permita utilizatorilor
sa caute mai eficient sau ambele. De exemplu, unii spider-i mentin o
lista de cuvinte din titlu, subtitlu si legaturi, impreuna
cu cele mai utilizate 100 de cuvinte din pagina si fiecare cuvant din
primele 20 de linii de text. Se pare ca Lycos utilizeaza aceasta
modalitate de indexare a continutului paginilor web.
Alte sisteme, precum
AltaVista.com, merg in alta directie, indexand toate cuvintele din
pagina, inclusiv toate cuvintele de legatura sau
"nesemnificative". Aceasta impingere catre completitudine are si
alte modalitati de functionare, mai ales prin utilizarea
meta-tag-urilor.
Meta-tag-urile permit
proprietarului unei pagini sa specifice cuvintele cheie si conceptele
sub care va fi indexata pagina respectiva. Acest lucru poate fi
folositor in cazul in care cuvintele din pagina pot avea doua sau mai
multe semnificatii, meta-tag-urile ghidand motorul de cautare in
alegerea celei mai corecte semnificatii pentru cuvintele respective.
Exista de asemenea si anumite pericole in utilizarea acestor tag-uri,
deoarece un proprietar neatent sau fara scrupule ar putea adauga
meta-tag-uri care sa se potriveasca celor mai populare subiecte,
fara ca acestea sa aiba nimic cu continutul in sine al
paginii. Pentru o protectie impotriva acestei practici, spider-ii
coreleaza de obicei continutul paginii cu meta-tag-urile, respingand
tag-urile care nu se potrivesc cu cuvintele din pagina.
Toate cele de mai sus
presupun faptul ca proprietarul paginii sau site-ului doreste ca
pagina/site-ul sa fie inclus in rezultatele activitatii
motoarelor de cautare. De multe ori proprietarii nu doresc includerea
intr-un motor de cautare major sau nu doresc indexarea anumitor pagini
dintr-un site. Pentru acest lucru a fost dezvoltat protocolul de excludere al
robotilor (robot exclusion protocol). Acest protocol, implementat in
sectiunea de meta-tag-uri de la inceputul unei pagini web, comunica
robotului de cautare sa nu indexeze pagina si/sau sa nu
urmareasca nici unul din link-urile din pagina respectiva.
Dupa ce spider-ii
au terminat sarcina de gasire a informatiilor in paginile web
(trebuie sa notam faptul ca aceasta sarcina nu se
termina niciodata - din cauza naturii mereu schimbatoare a
web-ului, spider-ii indexeaza pagini in permanenta), motorul de
cautare trebuie sa stocheze informatiile adunate intr-o
modalitate utilizabila. Exista astfel doua componente care fac
datele adunate accesibile utilizatorilor:
informatia stocata cu datele;
metoda in care este indexata informatia.
In cel mai simplu caz,
un motor de cautare doar va stoca cuvintele si URL-ul unde au fost
gasite. In realitate, acest lucru ar face dintr-un motor de cautare
unul cu utilizari limitate, deoarece nu ar exista nici o modalitate de a
spune daca acel cuvant a fost utilizat intr-un context important sau unul
trivial in pagina respectiva, nici daca acel cuvant a fost utilizat o
singura data sau de mai multe ori, sau daca pagina contine
legaturi catre alte pagini cu acel cuvant. Cu alte cuvinte, nu ar fi
nici o posibilitate de a construi un clasament care ar incerca sa prezinte
cele mai utile pagini la inceputul listei de rezultate.
Pentru a crea si
afisa cele mai utile rezulte, cele mai multe motoare de cautare
stocheaza mult mai multe date decat cuvantul si URL-ul in care a fost
gasit. Un motor ar putea stoca numarul de aparitii al cuvantului
in pagina, putand de asemenea sa asigneze cate o "greutate"
fiecarei intrari, cu valori mai mari atasate cuvintelor care
apar catre inceputul documentului, in subtitluri, legaturi,
meta-tag-uri sau titlul paginii. Fiecare motor de cautare comercial are
diferite formule sau modalitati pentru asignarea greutatii
pentru cuvintele din index. Acesta este unul din motivele pentru care o cautare
dupa acelasi cuvant in motoare de cautare diferite va produce
liste de rezultate diferite, cu paginile prezentate in ordini diferite, chiar
daca sunt indexate aceleasi pagini.
Fara a
tine cont de combinatia precisa de informatii
aditionale stocate de un motor de cautare, datele vor fi stocate in
mod codat, pentru a economisi spatiul de stocare. De exemplu, documentul
original de prezentare al Google.com utiliza 2 bytes, fiecare din 8 biti,
pentru a stoca informatii referitoare la greutate: cuvantul era scris cu litere
mari, marimea fontului, pozitia sau alte informatii necesare
clasificarii. Fiecare factor putea lua 2 sau 3 biti in cei 2 bytes,
avand ca rezultat stocarea unui volum mare de informatii intr-un
spatiu foarte compact.
Dupa ce informatia este
compactata/condata, aceasta este gata de indexare. Un index are un
singur scop: permite gasirea foarte rapida a informatiei.
Exista mai multe modalitati de a construi un index, dar una din
cele mai eficiente modalitati este utilizarea unui tabel hash (hash
table). Prin hashing, se aplica o formula matematica pentru
atasarea unei valori numerice fiecarui cuvant, formula fiind
construita pentru a distribui in mod egal intrarile de-a lungul unui
numar predeteminat de diviziuni. Distributia numerica este
diferita de distributia cuvintelor din alfabet, aceasta fiind cheia
eficientei unui tabel hash.
In limba engleza, de exemplu, exista unele
litere cu care incep cele mai multe cuvinte, in timp ce alte litere sunt la
inceputul a mai putine cuvinte (comparati litera "M" din
dictionar cu litera "X"). Aceasta inegalitate inseamna ca
gasirea unui cuvant care incepe cu o litera mai "populara" ar
putea lua mai mult timp decat gasirea unui cuvant care incepe cu o
litera mai putin utilizata la inceputul cuvintelor. Prin hashing
se elimina aceasta diferenta si se reduce timpul mediu
pentru a gasi o intrare. Tot prin hashing se separa cuvintele de
indecsii in sine. Tabela hash contine numarul hash impreuna
cu un pointer catre datele efective, date care pot fi sortate in orice
directie. Combinatia de indexare si stocare eficienta face
posibila obtinerea rapida a rezultatelor, chiar daca
utilizatorul creeaza o interogare complexa.
Cautarea
printr-un index presupune construirea unei interogari de catre
utilizator si transmiterea ei catre motorul de cautare.
Interogarea poate fi simpla, alcatuita din minim un cuvant sau
mai complexa, necesitand operator booleeni, care permit rafinarea si
extinderea cautarii.
Operatorii booleeni
cei mai des utilizati sunt urmatorii:
AND - toti termenii separati prin
"AND" trebuie sa apara in pagina sau in document. Unele motoare
de cautare pot folosi "+" in loc de "AND";
OR - cel putin unul din termenii
separati prin "OR" trebuie sa apara in pagina sau document;
NOT - termenul sau termenii care urmeaza
dupa "NOT" nu trebuie sa apara in document. Unele motoare de
cautare pot folosi "-" in locul cuvintului "NOT";
FOLLOWED BY - unul din termeni trebuie sa
fie urmat in mod direct de catre altul;
NEAR - unul din termeni trebuie sa fie la
o distanta specificata in cuvinte de celalalt termen;
Ghilimele - cuvintele dintre ghilimele sunt
tratate sub forma de fraza, iar acea fraza trebuie sa fie
gasita in interiorul documentului sau paginii;
Cautarile definite prin operatorii booleeni
sunt cautari "literale", in care motorul cauta cuvintele sau
frazele exact cum sunt introduse. Acest lucru poate fi o problema in cazul
cuvintelor cu mai multe intelesuri. In cazul in care utilizatorul este
interesat doar in gasirea paginilor care contin doar unul din
sensuri, se pot astfel de interogari, dar ar fi mai util ca motorul de
cautare sa realizeze acest lucru in mod automat.
Astfel, una din ariile de cercetare in domeniul
motoarelor de cautare este cel al "cautarii bazate pe concepte".
Unele din aceste cercetari presupun utilizarea analizei statistice in
pagini care contin cuvintele sau frazele care sunt cautate, pentru a
gasi alte pagini in care utilizatorul ar putea fi interesat.
Alte domenii de cercetare privesc interogarile
bazate pe limbaj natural, putand astfel fi introduse interogari la fel ca
intrebarile puse oamenilor, fara a mai fi nevoie de operatori
booleeni sau structuri de interogari complexe. Cel mai important motor de
cautare care foloseste limbajul natural este AskJeeves.com, care
parseaza interogarile pentru a gasi cuvintele cheie, pe care le
aplica mai apoi indexului de site-uri construit. AskJeeves.com
lucreaza cel mai bine cu interogari simple, dar exista o
competitie deosebita in acest sens.
In tabelul
urmator se poate observa o comparatie intre trei motoare de
cautare foarte populare.
|
Motor de cautare
|
Google
https://google.com/
|
Yahoo! Search
search.yahoo.com
|
Teoma
https://www.teoma.com/
|
|
Link-uri pentru ajutor
|
https://www.google.com/help/index.html
|
https://help.yahoo.com/help/us/ysearch/basics/basics-04.html
|
https://static.wc.teoma.com/docs/teoma/about/searchtips.html
|
|
Marime (marimea variaza de la o zi la alta)
|
Peste 8 miliarde pagini. Aproximativ 25% nu sunt indexate pe deplin
(nu pot fi cautate cuvinte in interior). Paginile neindexate sunt
afisate in cazul in care interogarea se potriveste cu titlul sau cu
alte pagini care conduc la ele.
|
Peste 3 miliarde de pagini, indexate si interogabile in
intregime.
|
Pretinde ca are 1 miliard de pagini indexabile si
interogabile in intregime si inca 1 miliard indexate partial.
|
|
Facilitati si limitari
|
Clasificarea rangurilor este facuta cu PageRankT. Limitare
la 10 cuvinte pe cautare, excluzind OR. Indexeaza primii 101 KB din
pagini web si 120 KB din documente PDF.
|
Prescurtarile permit acces rapid la dictionar, sinonime,
patente, trafic, actiuni, enciclopedie etc.
|
Rang in functie de Subject-Specific PopularityT. Sugereaza
termini in rezultat pentru a-l rafina. Sugereaza pagini cu multe
link-uri in rezultate.
|
|
Cautare dupa fraza
|
Da. Utilizeaza " ". Utilizeaza si cuvinte de oprire in
fraza.
|
Da. Utilizeaza " ".
|
Da. Utilizeaza " ". Utilizeaza si cuvinte de oprire in
fraza.
|
|
Logica booleana
|
Partiala. AND este implicit intre cuvine. OR trebuie scris
cu litere mari. "-" pentru excludere. Nu permite paranteze sau imbricare.
|
Accepta AND, OR, NOT, AND NOT, (), toate scrise cu litere mari.
|
Partiala. AND este implicit intre cuvine. OR trebuie scris
cu litere mari. "-" pentru excludere. Nu permite paranteze sau imbricare.
|
|
+Necesita / -Excludere
|
- excludere
+ permite gasirea cuvintelor de oprire (ex: +in)
|
- excludere
+ permite gasirea cuvintelor comune '+in truth'
|
- excludere
+ permite gasirea cuvintelor de oprire (ex: +in)
|
|
Sub-cautare
|
La sfirsitul paginii de rezultat exista "Search within
results' pentru a introduce mai multi termini
|
Adaugare de termeni
|
Adaugare de termeni.
REFINE sugreaza sub-subiecte in rezultate
|
|
Clasificarea rezultatelor
|
Bazata pe popularitatea paginii masurata in
legaturi catre ea de la alte pagini: rang inalt daca multe
alte pagini se leaga la ea. Este implicat si FuzzyAND.
Rang si pe baza paginilor din cache, care pot sa nu fie cele mai
recente.
|
FuzzyAND automat.
|
Bazat pe
Subject-Specific PopularityT, legaturi catre o pagina
de la pagini inrudite.
|
|
Limitarea cimpurilor
|
link:
site:
allintitle:
intitle:
allinurl:
inurl:
Se gasesc si in optiunea "Advanced Search".
|
link:
site:
intitle:
inurl:
url:
hostname:
|
intitle:
inurl:
site:
geoloc:
|
|
Trunchiere
|
Nu. Cautare cu variante de terminatii si sinonime
separate prin OR:
airline OR airlines
|
Nu. Cautare cu variante de terminatii si sinonime
separate prin OR:
airline OR airlines
|
Nu. Cautare cu variante de terminatii si sinonime
separate prin OR:
airline OR airlines
|
|
Diferenta litera mare/litera mica
|
Nu.
|
Nu.
|
Nu.
|
|
Limba
|
Da, in "Advanced Search".
|
Da.
|
Da. Utilizare cu lang:
|
|
Limitare dupa data documentului
|
In "Advanced Search" si cu daterange:
|
In "Advanced Search"
|
In "Advanced Search"
|
|
Traducere
|
Da. Din/in Engleza din/in limbi majore internationale
si
chineza,coreana,japoneza
|
Da.
|
|
Tabelul : Comparatie intre trei
motoare de cautare populare.
Meta-motoarele de cautare transmit interogarea
tastata de utilizator catre mai multe motoare de cautare in
acelasi timp, afisind catre utilizatori rezultatele tuturor
cautarilor, in toate motoarele de cautare. Acest tip de motoare
de cautare nu detine propria baza de date cu pagini indexate,
transmitind interogarile catre bazele de date detinute de
companiile care detin motoare de cautare.
Totusi, din ce in ce mai putine meta-motoare
de cautare permit gasirea de date in cele mai utile baze de date, ele
gasindu-si rezultatele din motoare de cautare gratuite sau de
dimensiuni mici ca si din directoare (de subiecte) mici si cu un
intens caracter comercial.
|
Meta-motoare de cautare
|
In ce cauta
|
Interogari complexe
|
Afisare rezultate
|
|
Vivisimo
https://www.vivissimo.com/
|
Cauta intr-un numar de motoare de cautare redus
si de o calitate indoielnica.
|
Accepta si translateaza cautarile complexe
cu operatori booleeni si limitari de cimp.
|
Rezultatele sunt insotite de subdiviziuni ale subiectului bazat
pe cuvintele din rezultate, dind de obicei temele majore rezultate.
|
|
Metacrawler
&
Dogpile metacrawler.com
dogpile.com
|
Cauta in Google, Yahoo, LookSmart, Teoma, Overture, FindWhat.
Include, fara sa mentioneze exemplicit, ranguri
cumparate.
|
Accepta logica booleana, mai ales in modurile de
cautare avansata.
|
Permit si
vizualizarea separata a rezultatelor fiecarui motor de
cautare.
|
Tabelul : Meta-motoare de
cautare.
Ce
este web-ul invizibil?
Partea vizibila a
web-ului este ceea ce se poate obtine in rezultatele motoarelor de
cautare sau in directoarele de subiecte. Web-ul invizibil este acea parte
din web care nu se poate obtine in rezultatele cautarii precum
si alte link-uri continute in aceste tipuri de pagini.
Baze de date : cea mai mare parte a web-ului
invizibil este alcatuita din continutul al mii de baze de date
specializate care pot fi cautate prin web. Rezultatele cautarii
in multe din aceste baze de date sunt transmise catre utilizatorul final
sub forma de pagini web care sunt generate doar ca raspuns la
interogarea utilizatorului. Asemenea pagini nu sunt stocate nicaieri,
fiind mai ieftin si mai rapid de generat in mod dinamic raspunsul
fiecarei interogari decat de stocat toate paginile posibile
continand toate raspunsurile posibile la intrebarile sau
interogarile diversilor utilizatori.
Paginile excluse: exista anumite tipuri
de pagini care sunt excluse din rezultatele motoarelor de cautare din
cauza politicilor. Nu exista nici un motiv tehnic ca aceste pagini sa
nu fie incluse in rezultat, fiind mai mult o chestiune de selectare includerii
sau neincluderii in baze de date deja uriase si a caror interogare
produce un venit nesemnificativ.
De ce sunt unele pagini invizibile ? Exista
doua motive pentru care un motor de cautare nu contine o
pagina: 1. motive tehnice care interzic accesul si 2. decizia de a
exclude.
Barierele tehnice pot fi impartite
in doua categorii:
Este necesara scrierea sau
inteligenta. Daca singura modalitate de a accesa o pagina web
este de a scrie ceva sau de a selecta o combinatie de optiuni,
motoarele de cautare nu pot face acest lucru. Explicatia este ca
robotii de cautare traverseaza web-ul pe baza legaturilor
dintre pagini; in cazul in care nu exista nici o legatura
catre o pagina, robotii nu o pot "vedea". De asemenea,
robotii nu pot alege una sau mai multe optiuni inainte de a parcurge
o pagina. Paginile generate dinamic pot sa nu fie de asemenea incluse
in rezultate, deoarece aceste pagini nu sunt stocate, avand continut unic,
generat la fiecare cerere.
Necesitatea autentificarii. Toate
site-urile care necesita autentificare sunt inchise motoarelor de
cautare, deoarece robotii ar avea nevoie de ceva necunoscut
(username/parola, de exemplu). Exista milioane de astfel de site-uri
care necesita autentificare, deoarece continutul acestora nu este
gratuit sau au impus altfel de restrictii, de exemplu.
Excluderea intentionata a paginilor.
Motoarele de cautare pot sa nu includa in index pagini deoarece
formatul acestora sau al documentelor este accesat rar sau nu poate fi indexat
in mod corespunzator. Nu exista nici un motiv tehnic pentru a le
exclude ci doar o politica a companiei detinatoare a motorului
de cautare. Motivul este urmatorul: bazele de date ale motoarelor de
cautare si robotii de cautare sunt optimizate pentru a citi
HTML. Alte tipuri de limbaje pot contine coduri sau necesitati
de formatare incompatibile cu HTML. De asemenea, paginile care contin numai
imagini sunt deseori omise, deoarece nu exista text care sa fie
inclus in index.
Exista si exceptii de la regula de mai
sus. Google.com, de exemplu, poate sa indexeze documentele PDF, DOC, PPT.
De asemenea, Google, Altavista si alte motoare de cautare au
directoare sau motoare de cautare specializate in indexarea /cautarea
imaginilor.
Din cele de mai sus se poate deduce ca este
dificil de prezis ce site-uri sau tipuri de site-uri sau parti din
site-uri nu fac parte din web-ul invizibil, existand la mijloc cativa
factori:
Ce site-uri isi replica o parte din
continut in pagini statice (hibrid de web vizibil si invizibil);
Ce site-uri isi replica tot
continutul in pagini statice;
Ce site-uri nu isi replica deloc
continutul si trebuie interogate in mod direct (total invizibile);
Politicile motoarelor de cautare se pot
schimba in ceea ce priveste includerea/excluderea din index.

