Motor de cautare pe WEB
Pana in 1990 Internetul a fost folosit cu precadere de catre
cercetatori din domeniul academic, guvernamental si industrial. Cateva
aplicatii (de exemplu e-mail*, telnet, ftp) erau intr-adevar de
interes mai larg. Dar ceea ce a facut ca popularitatea sa sa creasca fara
precedent, in randul a milioane de utilizatori din toate domeniile, a fost o aplicatie noua, WWW (World Wide Web - sau mai simplu : WEB). Acesta aplicatie, inventata de fizicianul Tim
Berners Lee de la CERN, nu a
modificat nici una din facilitatile existente, in schimb le-a facut mai usor de
folosit. Impreuna cu programul de navigare Mosaic,
scris la Centrul National pentru Aplicatiile Supercalculatoarelor, WWW-ul a facut posibil ca un sit sa puna la dispozitie un numar de
pagini de informatii continand text, imagini, sunet si chiar imagini video in
miscare, in fiecare pagina existand legaturi (referinte) catre alte pagini,
lagaturi care puteau referi orice alta informatie din WWW. Printr-un sinplu "clic" cu mouse-ul pe o legatura,
utilizatorul este imediat "transportat" la pagina indicata de legatura, oriunde
in lume. De exemplu multe firme au pe WEB
o pagina principala cu intrari care trimit la pagini cu informatii asupra
produselor, liste de preturi, reduceri, suport tehnic (online), comunicare cu
angajatii, informatii despre actionari, etc. Pagina poate contine si referinte
la paginile altor sucursale (departate geografic) ale aceleiasi firme, toate
putand fi accesate ca un tot unitar.
Intr-un timp foarte scurt au aparut alte tipuri de pagini: hartio, tabele de
cotatii la bursa, cataloage de biblioteca, programe radio inregistrate si chiar
pagini continand textele complete ale unor carti carora le-au expirat
drepturile de autor (Mark Twain, Charles Dickens, etc). De asemenea multi
oameni au pagini personale (home pages).
In primul an de la lansarea Mosaic-ului, numarul de servere WWW a crescut de la 1000 la 7000.
Aceasta enorma crestere va continua, fara indoiala, in urmatorii ani si va
reprezenta, probabil, forta care va conduce tehnologia si utilizarea Internet-ului in mileniul III. Informatia de pe WEB se mareste in fiecare secunda, noi
si noi posibilitati deschizandu-se. Dar dupa o era de explozie a informatiei
trebuie in mod necesar sa apara si o era de structurare a sa. Multe pagini WEB au inca o structura haotica,
libertatea de legare a paginilor ducand deseori la structuri greu de urmarit si
inteles. Pe langa acest aspect caruia in ultimul timp i se acorda o mai mare
atentie, volumul mare de informatii creeaza inca o problema : problema gasirii
si regasirii informatiei dorite. Daca pentru regasirea informatiei fiecare
utilizator isi poate creea "Bookmarks-uri"
cu diferite structuri, cautarea unei informatii este o sarcina mult mai grea.
Adeseori cere experienta si chiar noroc. Din punct de vedere al structurii, WEB-ul reprezinta un graf cu o mare
conectivitare (se poate avansa conjectura ca 90% din el este un graf conex,
langa care coexista insulite mici neconectate). Astfel ca teoretic, pornind de
la o pagina situata in aceste cel mai mare subgarf conex, poti parcurge 90% din
informatia de pe Web, de fapt cvasitotalitatea
informatiei de larg interes. Algoritmi de parcurgere si cautare intr-un graf
conex exista. Dar problema nu este gasirea unui algoritm de parcurgere, ci
timpul necesar acestei cautari, datorita dimensiunii grafului. Se pot imagina
automate care sa caute pe Internet
(pe nivele de exemplu, cautarea in adancime avand un grad prea mare de
recursivitate), dar parcurgerea informatiilor intregului Web - datorita si vitezei
conexiunilor - este o sarcina practic imposibila.
De aceea se cauta noi modalitati de structurare a
informatiilor pe WEB. S-a inceput cu
liste de pagini principale, cu o descriere sumara a ceea ce se gaseste pe respectivul sit. Aceasta a dat rezultate o vreme,
dar in scurt timp listele au capatat dimensiuni enorme, trecandu-se la
structurarea lor pe domenii si subdomenii. Dar si acestea s-au dovedit a nu fi
in stare sa ofere o cantitate de informatii suficienta utilizatorului care vrea
sa caute ceva pe WEB. Munca de
intretinere a informatiilor era enorma, si chiar solutia de a lasa in sarcina
realizatorului paginilor desrierea acestora si inscrierea in baza de date nu
garanta veridicitatea informatiilor si controlul "expirarii" informatiei -
mutare, modificare, stergere. O idee novatoare a fost inventarea unor "Motoare de cautare" (numite si "masini
de cautare", "roboti de cautare", "web spiders", etc). Ele au sarcina sa
parcurga subarbori ai grafului Internet
cu scopul de a strange informatii despre continutul paginilor gasite. Volumul
de informatii este enorm, eterogenitatea lor este foarte mare, deci gasirea
unui algoritm de extragere automata a informatiilor semnificative pentru o
pagina nu este un lucru foarte usor. Desi majoritatea paginilor au un titlu,
aceste este de cele mai multe ori prost ales, nespunand mare lucru despre
pagina in sine (ex: "Pagina lui Ghiorghita"). Exista mai multe euristici de
extragere a informatiilor semnificative despre o pagina. Unele motoare de
cautare retin titlul, textele senzitive care duc la pagina, texte puse in
evidenta. Altele incearca sa retina si cuvintele care apar mai des in pagina
(exceptandu-le pe cele care nu sunt semnificativa (conjunctii, verbe). Aceasta
ultima strategie are dezavantajul ca necesita un timp computational al motorului de cautare prea mare.
Varianta de rulare pe fiecare sit a
unui program de parcurgere a paginilor este greu acceptabila datorita problemelor de securitate care pot apare.In
ultimele versiuni HTML (Hypertext Markup
Language) - formatul de scriere al paginilor WEB au fost introduse TAG-uri
(portiuni de text HTML care au in
general ca scop sa instruiasca programul de vizualizare al paginii cum sa
afiseze textul, imaginile, etc) prin care se pot specifica in mod explicit - de
catre autorul paginii - descrieri ale paginii si cuvinte cheie care sa trimita
la pagina respectiva. Aceasta ar fi o solutie de viitor, dar multi producatori
de pagini web nu includ in paginile lor aceste TAG-uri, din necunoastere sau comoditate. O combinare a acestor
strategii pare a fi solutia la momentul actual.
Alta problema este orientarea cautarii intr-un mod pragmatic.
Daca un motor de cautare ar indexa
(parcurge si strange referinte despre) o mare parte a Internet-ului, la sfarsitul indexarii primele pagini ar fi deja
expirate (modificat continutul, mutate sau sterse). In acelasi timp ar trebui
selectate informatiile de larg interes, in dauna celor personale de exemplu sau
a celor de interes local. Exista TAG-uri
prin care producatorii pot specifica ca paginile respective nu "merita" a fi
indexate dar extrem de putini fac efortul de a le include in paginile lor, mai
ales ca de obicei orice producator crede ca pagina lui este importanta. In
acelasi timp, o cautare haotica poate ajunge in zone ale Internet-ului pline de pagini "abandonate" de proprietarii lor -
pagini neactualizate, pagini de incercare, etc. De aceea se prefera in general
sa se indexeze pe cat posibil pagini la cererea posesorului - in premisa ca cel
care are ceva important de prezentat isi va da interesul sa isi promoveze
produsele. In lipsa acestor cereri de indexare (care apar in general dupa ce
motorul de cautare a capatat o oarecare popularitate) se poate merge recursiv
pe link-urile (legaturile) externe
extrase din paginile deja existente. Probabilitatea ca unj motor de cautare sa
ajunga intr-un punct mort (sa termine de indexat intreg subgraful conex din
care porneste) este practic nula. In afara de aceasta se pot stabili si
politici de "reindexare" in ideea ca referintele deja existente despre pagini
mai vechi pot fi incorecte.
In viitor ar trebui
gasite si alte solutii pentru problemele care apar - volumul din ce in ce mai
mare de date, supraincarcarea nodului de retea in care se face indexare,
scaderea vitezei de transmitere a datelor odata cu "departarea" de nodul in
care se strang informatiile. In aceste conditii, utilizarea in viitor a
motoarelor de cautare tematice, regionale sau cu intercooperare este
previzibila. Serverele de baze de date actuale s-ar putea dovedi ineficiente,
fiind necesare noi principii de organizare si distribuire a informatiei
In conluzie, proiectarea si realizarea unui motor de cautare este o sarcina
dificila, trebuind sa indeplineasca o seama de conditii ca:
capaciate
de stocare mare
cautare
rapida
euristica
bine aleasa, cu posibilitati de schimbare a ei in functie de noile tendinte de
organizare a paginilor observate pe web
posibilitati de adaugare cu efort minim a altor metode de extragere a
informatiilor din pagini si de orientare a cautarii.
posibilitatea de implementare pe numeroase platforme, pentru a beneficia de
ultime noutati hardware.
sistem de
operare gazda multitasking si orientat pe tehnologia client - server.
posibilitati de extindere a motorului de cautare la un sistem distribuit.
posibilitati de implementare ulterioara de alte metode de cautare in baza de
date deja existenta
robustete:
aplicatia trebuie sa faca fata posibilelor caderi de tensiune, blocaje in retea
fara a fi nevoie interventia unui specialist pentru a o reinitializa
posibilitati de a accesa alte tipuri de servere de baze de date
posibilitati de coexistare in acelasi timp a mai multor tipuri de organizari a
datelor, de exemplu pentru a inlocui treptat un tip de organizare cu altul.
Lucrarea de fata isi propune sa urmareasca realizarea
unei aplicatii "Motor de cautare"
care sa indeplineasca cat mai bine aceste cerinte. Ca sistem de operare gazda
este ales UNIX-ul (sau clona sa mai
recente Linux) pentru robostetea sa
in gestionarea resurselor si a proceselor concurente, pentru implementarea sa
puternica a socketurilor si a algoritmilor de gestionare a conexiunilor TCP/IP . In afara de aceaste, UNIX este ales si pentru faptul ca
ofera o securitate foarte buna, un motor de cautare fiind susceptibil la
atacuri distructive de diferite tipuri, UNIX-ul
rezolvandu-si slabiciunile la foarte scurt timp de la aparitia
vulnerabilitatii. Portabilitatea sa pe
aproape toate tipurile de platforme hardware nededicate.
Limbajul de programare ales este C/C++, pentru flexibilitatea lui si compromisul intre facilitatile
de nivel inalt si portabilitatea cu accesul larg la resursele sistemului,
permitand sa se realizeze optimizari in sectiunile critice ale programului.. In
acelasi timp este ales si pentru facilitatile sale de ascundere a datelor si de compilare separata pe module.
Documentatia prezenta contine doua parti, prima
detaliind conceptele fundamentale care intervin in acest proiect (notiuni,
protocoale, specificatii). A doua parte
este dedicata proiectarii programului, urmarind specificarea cerintelor,
motivatiile diferitelor solutii alese si functionarea diferitelor module. Ca
anexa este prezentat codul sursa al programului.
La mijlocul anilor 1960, cand Razboiul Rece era in
punctul culminant, DoD-ul a vrut o retea de comanda si control care sa poata
supravietui unui razboi nuclear. Traditionalele retele telefonice cu comutare
de circuite erau considerate prea vulnerabile, deoarece pierderea unei linii
sau a unui comutator ar fi dus la distrugerea iremediabila a conexiunilor care
o foloseau. Pentru a rezolva problema, DoD s-a orientat catre agentia sa de
cercetare, ARPA (mai tardiu DARPA, acum ARPA din nou) : (Defence) Advanced
Research Projects Agency - Agentia de Cercetare pentru Proiecte Avansate (de
Aparare).
ARPA a fost un raspuns la lansarea Sputnik-ului de
catre Uniunea Sovietica in 1957 si avea misiunea de a dezvolta tehnologia care putea fi utila scopurilor
militare. ARPA nu avea savanti sau laboratoare, activitatea agentiei constand
in furnizarea de fonduri si contracte universitatilor si firmelor care aveau
idei promitatoare.
O parte din primele fonduri au mers catre universitati
in vederea studierii comutarii de pachete, o idee radicala la acea vreme; idee
fusese sugerata de Paul Baram intr-o serie de rapoarte ale Corporatiei RAND
publicate la inceputul anilor 1960. Dupa discutii cu diversi experti, ARPA a
decis ca reteaua de care avea nevoie DoD trebuia sa fie o retea cu comutare de
pachete, constand intr-o subretea si din calculatoare gazda.
Subreteaua
trebuia sa fie formata din minicalculatoare numite IMP-uri (Interface Message
Processors - procesoare de mesaje de interfata) conectate prin linii de
transmisie. Pentru o siguranta mai mare, fiecare IMP trebuia legat la cel putin
alte doua IMP-uri. Subreteaua avea sa fie o subretea datagrama, astfel ca daca
unele linii sau IMP-uri se defectau, mesajele puteau fi redirijate pe cai
alternative.
In afara de subretea era insa nevoie de programe, asa
ca Larry Roberts de la ARPA a convocat in vara anului 1969, la Snowbird, Utah,
o intalnire intre cercetatori din domeniul retelelor, cei mai multi din ei
proaspat absolventi de facultate. Absolventii se asteptau ca niste experti in
retele sa le explice proie ctarea si software-ul retelei si ca fiecare din ei
sa primeasca apoi sarcina de a scrie o parte din programe. Ei au ramas insa
muti de uimire cand au constatat ca nu exista nici un expert in retele si nici
o proiectare serioasa. Ei trebuiau sa-si dea seama singuri ce au de facut.
Cu toate aceste, in decembrie 1969 incepea deja sa
functioneze o retea experimentala cu patru noduri, la UCLA, UCSB, SRI si
Universitatea din Utah. AU fost alese aceste patru institutii, pentru ca toate
aveau un numar mare de contracte cu ARPA si toate aveau calculatoare gazda
diferite si complet incompatibile (doar ca sa fie treaba mai amuzanta). Pe
masura ce se aduceau si instalau mai multe IMP-uri, reteaua crestea rapid; in
scurt timp s-a intins pe tot spatiul Statelor Unite.
Mai tarziu, programele pentru IMP-uri au fost
modificate pentru a permite terminalelor sa se lege direct la un IMP special,
numit TIP (Terminal Interface Procesor - procesor de interfata a terminalelor),
fara sa fie nevoie sa treaca printr-o gazda.
Pe langa ajutorul oferit pentru dezvoltarea tanarului
ARPANET, ARPA a finantat de asemenea cercetari in domeniul retelelor de
sateliti si retelelor radio cu pachete. Intr-o faimoasa demonstratie, un camion
care circula in Californiafolosea reteaua radio pentru a trimite mesaje pentru
SRI, aceste mesaje erau retransmise apoi prin ARPANET pe Coasta de Est, iar de
aici mesajele erau expediate catre University College din Londra prin reteaua
de sateliti. Acest lucru permitea unui cercetator din camion sa utilizeze un
calculator din Londra, in timp ce calatorea prin California.
Aceste experiment a demonstrat totodata ca
protocoalele ARPANET nu erau potrivite pentru a rula pe mai multe retele.
Observatia a dus la noi cercetari asupra protocoalelor, culminand cu inventia
modelului si protocoalelor TCP/IP. TCP/IP a fost special proiectat pentru a trata
comunicatia prin inter-retele, un lucru care se dovedea din ce in ce mai
important, pe masura ce noi retele se legau la ARPANET. Pentru a incuraja
aceste noi protocoale, ARPA a semnat cateva contracte cu BBN si cu University
of California din Berkeley pentru a
integra protocoalele in Berkeley UNIX. Cercetatorii din Berkeley au dezvoltat o
interfata de programare cu reteaua (soclurile) si au scris numeroase aplicatii,
utilitare si programe care sa simplifice interconectarea.
Momentul era perfect. Multe universitati tocmai
achizitionasera un al doilea sau al treilea calculator VAX si un LAN care sa le
conecteze, dar nu aveau nici un fel de programe de interconectare. Cand a
aparut 4.2BSD, cu TCP/IP, socluri si multe utilitare de retea, pachetul complet
a fost adoptat imediat. Mai mult chiar, folosind TCP/IP, LAN-urile se puteau
lega simplu la ARPANET, si multe LAN-uri au facut acest lucru.
In 1983, ARPANET-ul , cu 200 de IMP-uri si cu sute de
gazde era stabil si se bucura de succes. In acest moment, ARPA a incredintat
adiministrarea retelei Agentiei de Comunicatii a Apararii (Defense
Communications Agency - DCA), pentru a o folosi ca retea operationala. Primul
lucru pe care l-a facut DCA a fost sa izoleze portiunea militara (aproximativ
160 de IMP-uri din care 110 in Statele Unite si 50 in strainatate) intr-o
subretea separata, MILNET, si sa prevada porti stricte intre MILNET si
subreteaua de cercetare ramasa.
In timpul anilor 1980 au fost conectate la ARPANET
multe alte retele, in special LAN-uri. Pe masura ce crestea dimensiunea
retelei, gasirea gazdelor devenea tot mai costisitoare; de aceea a fost creat
DNS (Domain Naming System - Sistemul Numelor de Domenii), care organiza
masinile in domenii si punea in corespondenta numele domeniilor cu adrese IP. De
atunci incoace, DNS a ajuns sa fie un sistem distribuit, generalizat, folosit
pentru a memora diverse informatii referitoare la procedurile de atribuire a
numelor.
In 1990 ARPANET-ul era deja surclasat de retele mai
moderne carora le daduse nastere el insusi. Prin urmare, ARPANET-ul a fost
inchis si demontat, dar el continua sa traiasca in inima si mintea
specialistilor in retele de pretutindeni. MILNET functioneaza totusi in continuare.
La sfarsitul anilor 1970, NSF (U.S. National Science
Foundation) a remarcat enormul inpact pe care ARPANET-ul il avea asupra
cercetarii universitare, reteaua permitand savantilor din toata tara sa
partajeze date si sa colaboreze la proiecte de cercetare. Dar pentru a se
conecta la ARPANET, o universitate trebuia sa aiba un contract de cercetare cu
DoD, iar multe universitati nu aveau. Lipsa accesului universal a determinat
NDF-ul sa organizeze o retea virtuala, CSNET, centralizata in jurul unei
singure masini de la BBN care asigura suport pentru linii telefonice, si care
avea conexiuni cu ARPANET-ul si cu alte retele. Folosind CSNET, cercetatori
puteau suna si lasa posta electronica pentru a fi citita mai tarziu de alte
persoane. Era simplu si functiona.
In 1984 NSF a inceput sa proiecteze un succesor de
mare viteza al ARPANET-ului care sa fie deschis tuturor grupurilor de cercetare
din universitati. Pentru a avea ceva concret cu care sa inceapa, NSF a hotarat
sa construiasca o coloana vertebrala care sa lege centrele sale de
supercalculatoare din sase orase: San Diego, Boulder, Champaign, Pittsburg,
Ithaca si Princeton. Fiecare calculator a primit cate un frate mai mic (un calculator LSI-11) numit fuzzball. Fuzzball-urile
au fost legate cu linii inchiriate de 56kbps si au format subreteaua - aceeasi
tehnologie hardware ca cea folosita la ARPANET. Oricum, tehnologia software era
diferita: fuzzball-urile utilizau TCP/IP de la bun inceput; prin urmare acesta
a fost primul WAN TCP/IP.
NSF a finantat, de asemenea un numar de aproximativ 20
de retele regionale care se conectau la coloana vertebrala. Reteaua completa,
car eincludea coloana vretebrala si retelele regionale, a fost numita NSFNET. Aceasta a fost conectata la
ARPANET printr-o legatura intre un IMP si un fuzzball din laboratorul
Carnegie-Mellon.
NSFNET-ul a reprezentat un succes instantaneu si a
fost suprasolicitat inca de la inceput. S-a trecut la realizare a unei coloane
vertebrale cu fibra optica de 448kbps, apoi in 1990 s-a ajuns la viteza de 1.5
Mbps.
Cresterea a continuat insa, iar NSF a realizat ca
guvernul nu poate finanta conectarile la nesfarsit. In consecinta, NSF a
incurajat MERIT, MCI si IBM sa formeze o corporatie nonprofit, ANS (Advanced
Networks and Services - Retele si Servicii Avansate), ca un pas pe drumul spre
comercializare. In 1990, ANS a preluat NSFNET inlocuind legaturile de 1.5Mbps
cu legaturi de 45 Mbps, formand ANSNET
In decembrie 1991, Congresul Statelor Unite a aprobat
un proiect de lege care autoriza NREN (National Research and Educational
Network), ca succesorul din domeniul cercetarii al NSFNET-ului, functionand
insa la viteze de ordinul gigabitilor. Obiectivul era sa se realizeze inainte
de sfarsitul mileniului o retea nationala de 3 Gbps. Aceasta retea este gandita
ca un prototip al mult discutatei super-magistrale informationale.
Deoarece numeroase companii aveau retele IP
comerciale, in 1995 coloana vertebrala a NSFNET-ului nu mai era necesara pentru
conectarea retelelor regionale ale NSF-ului. Cand America Online a cumparat
ANSNET-ul in 1995, retelele regionale ale NSF-ului au fost deconectate si au
fost nevoite sa cumpere servicii IP pentru a se conecta. Companiile de
comunicatii au fost obligate sa intre in competitie, prin stipularea obligatiei
oricarui producator de servicii sa se lege la cel putin 4 NAP-uri (Network
Acces Point).
Alte tari si regiuni construiesc si ele retele
compatibile cu NSFNET. In Europa, de exemplu, EBONE este o coloana vertebrala
IP pentru organizatii de cercetare si EuropaNet este o retea orientata mai mult
pe domeniul comercial. Fiecare tara din Europa are una sau mai multe retele
nationale, care sunt, in linii mari, similare cu retelele regionale NSF.
Numarul retelelor, masinilor si utilizatorilor conectati la ARPANET a crescut rapid dupa ce
TCP/IP a devenit, la 1 ian 1983, unicul protocol oficial. Cand au fost
conectate NSFNET si ARPANET, cresterea a devenit exponentiala. S-au alaturat
multe retele regionale, si s-au realizat legaturi cu retele din Canada, Europa
si Pacific.
Candva, pe la mijlocul anilor 1980, lumea a inceput sa
vada colectia de retele regionale ca fiind un "internet" (inter-retea), apoi ca
fiind Internet-ul; nu a existat insa nici o inaugurare oficiala de
catre vreo organizatie comerciala sau politica.
Cresterea a continuat exponential si in 1990
Internet-ul ajunsese sa cuprinda 3000 de
retele si 200.000 de calculatoare. In 1992 a fost atasata gazda cu numarul
1.000.000. In 1985 existau mai multe coloane vertebrale, sute de retele de
nivel mediu (adica regionale), zeci de mii de LAN-uri, milioane de gazde si zeci
de milioane de utilizatori. Marimea Internetului se dubleaza aproximativ la
fiecare an.
Mare parte din crestere se datoreaza conectarii la
Internet a retelelor existente. Printre acestea s-au numarat in trecut SPAN,
reteaua fizica spatiala a NASA, HEPNET, o retea de fizica energiilor inalte,
BITNET, reteaua de sisteme de calcul a IBM-ului, EARN, o retea academica
europeana foarte utilizata in Europa de Est, si multe altele. Sunt in functiune
numeroase legaturi transatlantice, cu viteze intre 64kbps si 2Mbps, precum si
legaturi prin satelit.
Substanta care tine legat Internetul este modelul de
referinta TCP/IP si stiva de protocoale TCP/IP. TCP/IP face posibile servicii
universale, putand fi comparat cu sistemul telefonic sau cu adoptarea latimii
standard pentru caile ferate in secolul 19.
Ce inseamna de fapt sa fii pe Internet? O definitia ar
putea fi ca o masina este pe Internet daca foloseste stiva de protocoale
TCP/IP, are o adresa IP si are posibilitatea de a trimite pachete IP catre
masinile din Internet. Simpla posibilitate de a transmite posta electronica nu
este suficienta, deoarece posta
electronica este redirectata catre multe retele din afara Internet-ului.
Oricum, subiectul este oarecum umbrit de faptul ca multe calculatoare personale
pot sa apeleze un furnizor de servicii Internet prin modem, sa primeasca o
adresa IP temporara si apoi sa transmita pachete IP catre alte gazde. Are sens
sa privim asemenea masini ca fiind conectate la Internet numai atata timp cat
ele sunt conectate la ruterul furnizorului de servicii.
Data fiind cresterea exponentiala a Internetului,
vechiul mod informal de functionare a Internetului nu mai este acceptabil. In
ianuarie 1992 a fost infiintata Societatea Internet, cu scopul de a promova
utilizarea Internetului si, probabil, de a prelua in cele din urma
administrarea sa.
Traditional, Internetul a avut patru aplicatii
principale, dupa cum urmeaza:
Posta electronica (e-mail) -
facilitatea de a compune, trimite si primi mesaje de la alti utilizatori
conectati la Internet.
Stiri
(news) - facilitatea de a accesa grupuri de discutii pe diferite domenii (a
primi mesaje si a trimite), si de a primi noutati dintr-un anumit domeniu.
Conectare la distanta (telnet,
Rlogin, etc) - facilitatea de a lucra pe un alt calculator decat cel la care
te-ai conectat.
Transfer
de fisiere (ftp) - facilitatea de a transmite (copia) fisiere intre doua gazde
legate la Internet
Aplicatia noua - WWW
(World Wide Web) a modificat
radical modul in care este privit Internet-ul. Ea nu a adus nimic nou ca
servicii, in schimb a adus o interfata prietenoasa pentru a accesa serviciile
mai sus amintite. Ea este atat de populara, incat unii utilizatori o confunda
cu insusi Internetul. A privi informatia din Internet ca fiind localizata in
nodurile unei retele virtuale de hyper-legaturi care inconjoara ca o plasa de
paianjen intrag pamantul pare a fi foarte sugestiva pentru utilizatori, de aici
si confuzia acestor legaturi virtuale cu
legaturile fizice intre calculatoare, care tind a capata o forma asemanatoare.
1.2.4
Protocolul IP (Internet Protocol)
Un loc potrivit pentru a porni studiul nivelului retea
in Internet este insusi formatul datagramelor IP. O diagrama IP consta intr-o
parte de antet si una de text(informatie). Antetul consta dintr-o parte de lungime
fixa (20 octeti) si una (optionala) de lungime variabila. Campurile antetului
sunt transmise in formatul big endian (cel mai semnificativ
primul). Procesorul SPARC este de tip big endian, dar Pentiumul este de
tip litle
endian, deci el trebuie sa faca o conversie a campurilor atat la
trimitere cat si la receptie. Asezarea campurilor in antet este urmatoarea:

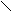
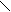
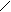

 32
biti
32
biti
|
Versiune
|
IHL
|
Tip serviciu
|
Lungime totala
|
|
Identificare
|
|
DF
|
MF
|
Deplasamentul fragmentului
|
|
Timp de viata
|
Protocol
|
Suma de control a antetului
|
|
Adresa sursei
|
|
Adresa destinatiei
|
|
Portiune
optionala
(zero sau mai multe cuvinte de 32 de biti)
|
| | | | | | | |
Campul "Versiune" memoreaza carei versiuni de protocol
ii apartine dadagrama. Prin includerea unui camp versiune in fiecare datagrama,
devine posibil ca tranzitia dintre versiuni sa tina luni, poate chiar ani, cu
unele masini ruland vechea versiune, si altele noua versiune.
Din moment ce lungimea antetului nu este constanta, un
camp din antet, IHL, este pus la dispozitie pentru a spune cat de lung este
antetul, in cuvinte de 32 de biti. Valoarea minima este 5, care se foloseste
atunci cand nu exista opiuni. Valoarea maxima a acestui camp pe 4 biti este 15,
ceea ce limiteaza antetul la 60 de octeti, si astfel campul de optiuni la 40 de
octeti. Pentru unele optiuni (de exemplu cea care inregistreaza calea pe care a
mers un pachet), 40 de octeti sunt prea putini, facand aceasta optiune
nefolositoare.
Campul tip
serviciu permite gazdei sa comunice subretelei ce tip de serviciu doreste.
Sunt posibile diferite combinatii de fiabilitate si viteza. Pentru vocea
digitizata livrarea rapida are prioritate fata de transmisia corecta. Pentru
transferul de fisiere, transmisia fara erori este mai importanata decat
transmisia rapida.
Campul insusi contine (de la stanga la dreapta), un
camp de 3 biti Precedenta, trei
indicatori (flags), D, T si R, plus 2
biti nefolositi. Campul Precedenta
este o prioritate (de la 0 - normal pana la 7 - pachet de control al retelei).
Cei trei biti indicatori permit gazdei sa specifice ce o afecteaza mai mult din
multimea . In teorie, aceste campuri permit ruterelor sa ia decizii intre,
de exemplu o legatura prin satelit cu o productivitate mare si o intarziere
mare si o linie dedicata cu productivitate mica dar si cu intarziere scazuta.
In practica, ruterele curente ignora campul Tip
serviciu
Lungimea
totala include totul din detagrama (inclusiv antetul).
Lungimea maxima este de 65535 octeti. In prezent, aceasta limita superioara
este tolerabila, dar in viitoarele retele cu capacitati de ordinul
gigaoctetilor vor fi necesare detagrame mai mari.
Campul Identificare
este necesar pentru a permite gazdei
destinatie sa determine carei datagrame apartine un nou pachet primit. Toate
fragmentele unei datagrame contin aceeasi valoare de identificare.
Urmeaza un bit nefolosit si apoi doua campuri de 1
bit. DF vine de la "Don't fragment" - A nu se fragmenta. Acesta este un ordin
dat ruterelor sa nu fragmenteze datagrama, pentru ca destinatia nu este
capabila sa le asambleze la loc. De exemplu, cand un calculator porneste,
memoria sa ROM poate cere sa i se trimita o imagine de memorie ca o singura
datagrama. Prin marcarea datagramei cu bitul DF, emitatorul stie ca acesta va
ajunge intr-o singura bucata, chiar daca aceasta inseamna ca datagrama va
trebui sa evite o retea cu pachete mai mici, dar mai rapida, pentru o ruta
suboptimala. Este necesar ca toate masinile sa accepte pachete de 576 octeti
sau mai mici.
MF
vine de la More Fragments (fragmente aditionale). Toate fragmentele, cu
exceptia ultimului, au acest bit activat. El este necesar pentru a a stii cand
au ajuns toate fragmentele unei datagrame.
Deplasamentul
fragmentulu spune unde este locul fragmentului curent in cadrul
datagramei. Toate fragmentele dintr- datagrama, cu exceptia ultimului, trebuie
sa aibe lungimea multiplu de 8 octeti - unitatea de fragmentare elementara. Din
moment ce sunt prevazuti 13 biti, exista un maxim de 8192 de fragmente de
datagrama, obtinandu-se o lungime maxima a datagramei de 65536 octeti, cu unul
mai mult decat campul Lungime totala.
Campul Timp de
viata este un contor folosit pentru a limita durata de viata a pachetelor.
Este prevazut sa contorizeze timpul in secunde, permitand un timp maxim de
viata de 255 secunde. El trebuie sa fie decrementat la fiecare salt (hop -
trecerea dintr-o retea in alta) si se presupune ca este decrementat de mai
multe ori cand sta la coada mai mult timp intr-un ruter. In practica, el
contorizeaza doar salturile. Cand contorul ajunge la zero, pachetul este
eliminat, trimitandu-se sursei un avertisment. Aceasta facilitate previne
hoinareala la nesfarsit a pachetelor prin Internet, ceea ce se poate intampla
daca tabelele de dirijare sunt incoerente.
Cand nivelul retea a asamblat o data grama completa,
are nevoie sa stie ce sa faca cu ea. Campul Protocol
spune carui proces de transport trebuie sa-l predea. TCP este o posibilitate,
dar tot asa sunt si UDP si alte cateva. Numerotarea protocoalelor este globala
pe intregul Internet si este definita in RFC 1700.
Suma de
control a antetului verifica numai antetul. O astfel
de suma de control este utila pentru detectarea erorilor generate de locatii de
memorie proaste in interiorul unui ruter. Algoritmul este de a aduna toate
jumatatile de cuvinte, de 16 biti, atunci cand acestea sosesc, folosind
aritmetica in complement fata de unu si pastrarea complementului fata de unu al
rezultatului. Pentru scopul acestui algoritm, suma de control a antetului este presupusa a fi zero dupa sosire.
Acest algoritm este mai robust decat folosirea adunarii normale. Observati ca
suma de control a antetului trebuie recalculata la fiecare salt, pentru ca cel
putin un camp se schimba intotdeauna (campul timp de viata), dar se pot folosi
trucuri pentru a accelera calculul.
Adresa
sursei si Adresa
destinatiei specifica numarul se retea si numarul de gazda. Adresele
Internet se vor discuta intr-o sectiune ulterioara.
Campul Optiuni a
fost proiectat pentru a oferi un subterfugiu care sa permita versiunilor
viitoare ale protocolului sa includa informatii care nu sunt prezente in
protocolul original, pentru a permite cercetatorilor sa incerce noi idei, si
pentru a evita alocare unui numar de biti rar folositi. Optiunile sunt de
lungime variabila. Fiecare incepe cu un cod de un octet, care identifica
optiunea. Unele optiuni sunt urmate de un camp de un octet reprezentand
lungimea optiunii, urmat de unul sau mai multi octeti de date. Campul Optiuni este completate pana la un
multiplu de 4 octeti. In aceste moment sunt definite cinci optiuni, care sunt
listate mai jos, dar nu toate ruterele le suporta pe toate.
|
Optiune
|
Descriere
|
|
Securitate
|
Mentioneaza cat de secreta este
datagrama
|
|
Dirijarea stricta pe baza sursei
|
Indica calea completa de parcurs
|
|
Dirijarea aproximativa pe baza sursei
|
Indica o lista a ruterelor ce nu trebuie
sarite
|
|
Inregistreaza calea
|
Fiecare ruter trebuie sa-si adauge
adresa IP
|
|
Amprenta de timp
|
Fiecare ruter sa-si adauge adresa si o
amprenta de timp
|
Optiunea Securitate
mentioneaza cat de secreta este informatia. In teorie, un ruter militar
poate folosi acest camp pentru a mentiona ca nu se doreste o dirijare prin
anumite tari pe care militarii le cansidera rauvoitoare. In practica, toate
ruterele il ignora, deci singura "functie" practica este sa ajute spionii sa
gaseasca lucrurile de calitate.da calea competa de la sursa la destinatie ca o
succesiune de adrese IP.
Optiunea Dirijarea
stricta pe baza sursei : Datagrama este obligata sa urmeze aceasta cale
precisa. Ea este deosebit de utila pentru administratorii de sistem pentru a
transmite pachete cand tabelele de dirijare sunt distruse, sau pentru a
depana/configura reteaua.
Optiunea Dirijarea
aproximativa pe baza sursei face posibila ocolirea anumitor regiuni
geografice din motive politice sau de alta natura.
Optiunea Inregistreaza
calea indica ruterelor de pe cale sa-si adauge adresele lor IP la campul
optiune. Aceasta permite administratorilor de sistem sa localizeze pene in
algoritmii de dirijare. Cand reteaua ARPANET a fost infiintata, nici un pachet
nu trecea vreodata prin mai mult de noua rutere, deci 40 de octeti erau
suficienti. Cum s-a mai spus, in prezent dimensiunea este prea mica.
Optiunea Amprenta
de timp este similara cu optiunea Inregistreaza ruta, cu exceptia faptului
ca in plus fata de inregistrarea adresei de 32 biti se adauga si o amprenta de
timp de 32 biti. Si aceast aoptiune este folosita tot pentru depanarea
algoritmilor de dirijare.
Fiecare gazda si ruter din Internet are o adresa IP,
care codifica adresa sa de retea si de gazda. Combinatia este unica: nu exista
doua masini in Internet cu acelasi IP. Toate adresele IP sunt de 32 de biti
lungime, si sunt folosite in campurile Adresa
sursa si Adresa destinatie ale
pachetelor IP. Masinile care sunt conectate la mai multe retele au adrese
diferite in fiecare retea. Formatele folosite pentru adresele IP sunt
urmatoarele :







 32
biti
32
biti
|
Retea
|
Gazda
|
|
Retea
|
Gazda
|
|
Retea
|
Gazda
|
|
Adresa de trimitere multipla
|
|
Rezervat pentru folosire viitoare
|
| | | | | | | | |
In functie de antetul adresei (0, 10, 110, 1110,
11110) adrese se impart respectiv in adrese de clasa A, B, C, D, E. Formatele
de clasa A, B, C si D permit pana la 126 retele cu 16 milioane de gazde
fiecare, 16.382 retele cu pana la 64.000 gazde fiecare, 2 milioane de retele cu
pana la 254 gazde fiecare (de exemplu LAN-uri) si multicast (trimitere
multipla).Zeci de mii de retele sunt conectate acum la Internet, si numarul se
dubleaza in fiecare an. Numerele de retea sunt atribuite de NIC (Network Information Center) pentru a evita conflictele.
Adresele IP, care sunt numere de 32 de biti, sunt
scrise in mod uzual in notatie zecimala cu punct. In aceste format, fiecare
dintre cei 4 octeti este scris in zecimal, rezultand valori intre 0 si 255. De
exemplu, adresa hexazecimala C0290614 este scrisa ca 192.41.6.20. Cea mai mica
adresa IP este 0.0.0.0 si cea mai mare este 255.255.255.255.
Valorile 0 si -1 au semnificatii speciale. Valoarea 0
reprezinta reteaua curenta sau gazda curenta. Valoarea -1 este folosita ca o
adresa de difuzare pentru a desemna toate gazdele din reteaua indicata.
Adresa IP 0.0.0.0 este folosita de gazde atunci cand
sunt pornite, dar nu mai este folosita ulterior. Adresele IP cu 0 ca numar de
retea se folosesc pentru a referi reteaua curenta. Astfel, o masina se poate
referi la propria retea fara a cunoaste numarul acesteia (ea trebuie insa sa
cunoasca clas aretelei, pentru a stii cate zerouri sa includa). Adresel care
contin numai 1-uri sunt folosite pentru a difuza in reteaua curenta (de obicei
este vorba de un LAN). Adresele cu numar de retea exact si cu numar de gazda
format numai din 1-uri se folosesc pentru a trmite pachete tuturor gazdelor de
la o anumita adresa de retea. In final, adresele 127.xx.yy.zz sunt rezervate pentru testari in
bucla locala (loopback). Pachetele trimise catre aceasta adresa nu sunt trimise
prin cablu; ele sunt prelucrate total si tratate ca pachete sosite. Aceasta
permite ca pachetele sa fie trimise propriei gazde, fara ca emitatorul sa-i cunosaca
adresa
WORLD WIDE WEB (sau mai simplu WEB sau WWW) este un
context arhitectural pentru accesul la documente raspandite pe mii de masini
din Internet, intre care exista legaturi. In 5 ani a evoluat de la o aplicatie
pentru transmiterea de date utile pentru fizica energiilor inalte la o
aplicatie despre cvare milioane de oameni cred ca este Internetul.
Popularitatea sa enorma se datoreaza faptului ca are o interfata grafica plina
de culoare, usor de utilizat de catre utilizatori si in acelasi timp ofera o
cantitate imensa de informatie despre orice subiect posibil
Web-ul, cunoscut si ca WWW a aparut in 1989 la CERN.
CERN are cateva acceleratoare utilizate de echipe mari de cercetatori din
tarile europene, pentru cercetari in fizica particulelor. Deseori aceste echipe
au membrii din peste 10 tari. Majoritatea experientelor sunt foarte complicate,
si necesita ani de pregatire si construire de echipamente. WEB-ul a aparut din
necesitatea de a permite cercetatorilor raspanditi in lume sa colaboreze
uytilizand colectii de rapoarte, planuri, desene, fotografii si alte tipuri de
documente aflate intr-o continua modificare.
Propunerea initiala pentru crearea unei colectii de
documente avand legaturi intre ele (WEB) a fost facuta de fizicianul Tim
Berners-Lee, fizician la CERN, in martie 1989. Primul prototip (bazat pe text)
era operational 18 luni mai tarziu. In decembrie 1991 s-a facut o demonstratie
publica la conferinta Hypertext '91, in San Antonio, Texas. Actiunea a
continuat in anul urmator, fiind incununata cu realizarea primei interfete
grafica, Mosaic, in februarie 1993.
Mosaic a fost atat de popular incat un an mai tarziu
autorul sau Mark Andreessen a parasit NCSA unde Mosaic-ul a fost dezvoltat,
pentru a forma o noua companie, Netscape Communication Corp. care se ocupa de
dezvoltarea de software pe WEB. Cand Netscape-ul a devenit o companie publica
in 1995, investitorii, care probabil au
crezut ca este vorba de un fenomen de tip Microsoft, au platit 1.5 mild dolari
pentru actiunile companiei. Aceste record a fost cu atat mai neasteptat cu cat
compania avea un singur produs, opera in deficit si anuntase probabilii
investitori ca nu se asteapta la beneficii in viitorul apropiat.
In 1994 CERN si MIT au semnat o intelegere de a forma
conhsortiul WORLD WIDE WEB, organizatie care are ca obiectiv dezvoltarea
WEB-ului, standardizarea protocoalelor si incurajarea interoperabilitatii intre
site-uri. Barnes Lee a devenit director. De atunci, sute de universitati si
companii au intrat in consortiu. MIT coordoneaza partea americana a
consortiului, in timp ce centrul de cercetari INRIA coordoneaza partea
europeana. Desi exista foarte multe carti despre WEB, cel mai bun loc pentru
gasirea unor informatii la zi despre el este (in mod natural) chiar WEB-ul.
Pagina consortiului are adresa htttp://www.w3.org. Cititorii interesati vor
gasi acolo legaturi la pagini care acopera toate documentele si activitatile
consortiului.
Din punct de vedere al utilizatorului, WEB-ul se
prezinta ca o colectie imensa de documente raspandite in toata lumea, numite pagini. Fiecare pagina poate sa contina legaturi (indicatori)
la alte pagini, aflate oriunde in lume. Utilizatorii pot sa aleaga o legatura
(de exemplu prin executia unui click) care ii va duce la pagina indicata de
legatura. Acest proces se poate repeta la nesfarsit, fiind posibil sa se
traverseze in acest mod sute de pagini legate intre ele. Despre paginile care
indica spre alte pagini se spune ca utilizeaza hypetext.
Paginile pot fi vazute cu ajutorul unui program de navigare (browser). Mosaic
si Netscape sunt cele mai cunoscute programe de navigare. Programul de navigare
aduce pagina ceruta, interpreteaza textul si comenzile de formatare continute in text si afiseaza pagina,
formatata corespunzator, pe ecran. Majoritatea paginilor de WEB incep cu titlu,
contin informatii si se termina cu adresa de posta electronica a celui care
mentine pagina. Sirurile de caractere care reprezinta legaturi la alte pagini
se numesc hyperlegaturi, sunt afisate
in mod diferit, fiind subliniate si/sau colorate cu o culoare speciala. Pentru
a selecta o legatura, utilizatorul va plasa cursorul pe zona respectiva
(utilizand mouse-ul sau sagetile de pe tastatura) si comanda selectia (cu
ajutorul mouse-ul sau apasand tasta ENTER). Desi exista programe de navigare
fara interfata grafica, ca de exemplu lynx,
ele nu sunt atat de utilizate ca programele de navigare grafice.
Modelul de comunicare intre serverul WEB si clientul
care acceseaza informatia este urmatorul (sa zicem ca aceseaza
https://www.w3.org/hypertext/WWW/TheProject.html) :
Programul de navigare determina URL
(pe baza selectiei)
Programul
de navigare intreaba DNS care este adresa IP pentru masina care se numeste
www.w3.org.
DNS
raspunde cu 18.23.0.23
Programul
de navigare realizeaza conexiunea TCP cu portul 80 al 18.23.0.23
Trimite o
comanda GET /hypertext/WWW/TheProject.html
Serverul
www.w3.org transmite fisierul "TheProject.html"
Conexiunea
TCP este eliberata
Programul
de navigare afiseaza formatat textul din "TheProject.html"
Programul
de navigare aduce si afiseaza toate imaginile din "TheProject.html"
"Limbajul" in care sunt descrise paginile WEB se
numeste HTML. El este derivat din SGML, si este format din seturi de tag-uri inserate in text, care dau
directive asupra modului in care sa se formateze textul. In functie de
posibilitatile hard ale sistemului pe care se vizualizeaza pagina, si de
posibilitatile browserului, pagina va fi afisata cu mai multe sau mai putine
caracteristici de formatare (un browser in mod text nu va putea folosi fonturi
de marimi diferite). Tagurile sunt texte cuprinse intre '<' si '>'.
Textul va trebui sa nu contina aceste caractere, aparitia lor trebuind
inlocuita cu metacaractere inlocuitoare ("<" si ">") la randul
lui, "&" trebuiue si el inlocuit cu metasecventa "&". Si alte
caractere se pot specifica prin metasecvente (de exemplu caractere care nu sunt
in setul standard ASCII).
Formatul unei pagini HTML se poate observa in textul
urmator:
<html>|
<head>
<title>
Pagina
personala a lui Mihai Voicu
</title>
</head>
<body>
Nu
am avut inca timp sa pun ceva interesant <br>
Incercati
vechea mea
<a
href="https://liga.math.unibuc.ro/~mihvoi">
pagina
</a>
</body>
</html>
Numele tagurilor nu sunt "case sensitive", doar
optiunile si argumentele pot face distinctie in anumite cazuri intre literele
mari si mici (de exemplu calea intr-un URL care se gaseste in tagul <a>)
Se observa ca textul este cuprins intre tagurile
<html> si </html>. El cuprinde o sectiune de "head" si una de
"body". Sectiunea de "head" contine informatii despre document care nu se vor
afisa in pagina (eventual se va afisa pe bara de titlu a ferestrei
browserului). Textul din sectiunea de "body" contine descrierea paginii propriu
zise. In cadrul textului caracterul de sfarsit de linie este ignorat, la fel si
taburile sau aparitile multiple de spatii (se retine numai unul). Pentru a
obtine fortarea trecerii la linie noua, se foloseste tagul "<br>". Altfel,
afisarea textului treve la linie noua numai daca s-a completat intreaga linie.
Aranjarea textului a fost facuta doar pentru a usura lizibilitatea, neavand
deci semnificatie pentru browser. Se observa si un hyperlink, realizat cu tagul
<a> care contine in interior un argument care specifica URL-ul care va fi
incarcat in cazul ca se selecteaza respectivul link. URL-ul (Uniform Resource Location) reprezinta o conventie de
localizare a unei resurse informationale. El cuprinde (de la dreapta la stanga)
identificarea fisierului referit pe masina pe care se afla, numele masinii pe
care se gaseste si modul (protocolul) de accesare a acesteia. De exemplu in
URL-ul din exemplu protocolul este http (acces prin portul 80 prin protocolul
HTTP), masina este liga.math.unibuc.ro iar identificarea paginii este "~mihvoi"
- adica pagina personala a userului mihvoi. Serverul HTTP va rezolva acest identificator la calea interna
/home/mihvoi/public_html/index.html. Se observa ca sarcina localizarii pe
server este sarcina serverului, care cunoaste propriul mod de identificare a
resurselor sale publice. Nu toate fisierele de pe un server WEB pot fi accesate
prin HTTP. De obicei paginile publice se afla in directoare speciale,
identificarea lor facandu-se cu calea relativa la acel director. Dac nu se
specifica decat calea relativa a unui director, serverul intoarce un fisier cu nume implicit (de obicei numit
index.html). Exista si alte conventii (de exemplu /~user/ reprezinta directorul
radacina al informatiilor publice ale userului "user". URI-ul este un caz particular de mai putin
cunoscutul URI (Uniforme Resource Identifier) care identifica unic pe Internet
resursele care se pot accesa prin diferite protocoale
Paginile WEB pot contine imagini (tagul <img>),
tabele (tagul <table>) , etc. In sectiunea de "head" se pot specifica
prin tagul "<meta>" informatii despre autor, firma de care apartine si
chiar informatii destinate motoarelor de cautare (descriere, cuvinte cheie,
etc).
Sistemul UNIX devine popular inca de le conceperea sa,
ruland pe masini de diferite puteri, de la microcalculatoare pana la mainframe-uri. Se compune din doua
parti:
programe si servicii care l-au facut atat de
popular: Shell, posta electronica,
editoare de text si procesoare de limbaj;
nucleul sistemului de operare, care
este suportul de executie al acestor programe.
In 1965, Bell Telephone Laboratories, General Electric
Company si Proiectul MAC de la M.I.T. lucreaza impreune la un nou sistem de
operare: Multics. Scopul era obtinerea unui sistem multiuser, sustinerea unei puteri mari de calcul si de stocare a
datelor, precum si posibilitatea de folosire in comun a acestor date. O prima
versiune a Multics-ului rula pe un
GE645, dar ea nu era comform asteptarilor. Bell Laboratories se retrage din
proiect. In incercarea de a-si dezvolta propriul proiect, Ken Thompson, Dennis
Ritchie si altii schiteaza un sistem de gestiune a fisierelor ce va evolua in
prima versiune de sistem de fisiere UNIX. Thompson a scris programe care
simulau comportarea sistemului de fisiere dorit si a intr-un mediu cu paginare
la cerere si chiar a scaris un mediu simplu pentru GE645. In acelasi timp, a
realizat un joc, "Calatorie in spatiu" in Fortran, pentru GECOS, dar programul
nu a avut succes pentru ca nava era greu de controlat, iar programul era
dificil de jucat. Mai tarziu, Thompson a gasit un calculator PDP 7, care oferea
un ecran grafic mai bun. Jocul pentru PDP 7 i-a permis acestuia sa cunoasca
calculatorul mai bine. Pentru a creea un mediu de dezvoltare mai bun, Thompson
si Richie implementeaza sistemul proiectat de ei pe PDP 7, creand o versiune
timpurie de sistem de fisiere UNIX, subsistemul de gestiune al proceselor si un
set mic de programe utilitare. Noul sistem de operare primeste numele de UNIX,
un joc de cuvinte la adresa numelui Multics, facut de Brian Kernigham.
Desi aceasta prima versiune de UNIX era comforma
asteptarilor, ea nu-si poate atinge potentialul pana nu este utilizata intr-un
proiect real. Astfel, pentru ca furniza un procesor de texte utilizat de
departamentul de evidenta a patentelor de la Bell Laboratoires, UNIX-ul este
mutat in 1971 pe un PDP 11. Sistemul avea dimensiuni mici:
16 Ko
sistemul de operare;
8 Ko
programele utilizator;
un disc de
512 Ko;
limita de
64Ko pentru un fisier.
Dupa succesul imediat al UNIX-ului, Thompson hotaraste
sa implementeze un compilator Fortran pentru noul sistem, dar in locul lui vine
cu un limbaj numit B, influentat de BCPL. B era un limbaj interactiv, cu
dezavantajele comune acestui tip de limbaj. un limbaj numit B, influentat de
BCPL. B era un limbaj interactiv, cu
dezavantajele comune acestui tip de limbaj, astfel incat Ritchie il dezvolta in
C, ceea ce permite generarea de cod,
declaratii de tipuri de date si definiri de structuri de date. In 1973, UNIX-ul
este rescris in C - un pas
extraordinar, care va avea un impact urias in acceptarea sa de catre
utilizatori. Numarul de instalari la Bell Laboratories este creste la 25, si se
formaza Grupul Sistemelor UNIX,
pentru a furniza suportul intern. In acest timp, AT&T nu poate vinde
produsele ce tin de calculatoare din cauza "decretului de incuviintare" semnat
in 1956 cu guvernul, dar furnizeaza sistemul de operare universitatilor, carora
le este necesar in scopuri educationale. AT&T nu a facut reclama, nici nu a
vandut si nici nu a sprijinit sistemul, in conformitate cu te4rmenii
"decretului de incuviintare". Totusi, popularitatea sistemului a crescut
constant. In 1974, Thompson si Ritchie publica o descriere a sistemului UNIX in
"Communications of ACM|, ce se va constitui intr-un punct favorabil in
acceptarea sa.
In 1977, numarul utilizatorilor UNIX creste la aproape
500, din care 125 erau universitati. UNIX devine popular in cadrul companiilor
telefonice, furnizand un mediu propice dezvoltarilor de programe, operatii de
tranzactii in retea si servicii in timp real. Licentele UNIX sunt furnizate
institutiilor comerciale precum si universitatilor. In 1977, Interactive System
Corporation devine primul "VAR" (Value Added Reseler) al sistemului UNIX. Anul
1977 marcheaza, de asemenea, momentul in
care sistemul UNIX a fost primul sistem portabil pe o masina non-PDP: Interdata
8/32. Odata cu cresterea posibilitatilor microprocesorului, alte companii au instalat
UNIX-ul pe noile lor masini; Insa simplitatea si claritatea au atras si multe
transformari, pe cai diferite, astfel ca au rezultat mai multe versiuni ale
sistemului de baza. In perioada 1977-1982, Bell Laboratories combina mai multe
variante AT&T intr-un singur sistem cunoscut sub numele comercial de UNIX
System III. Bell Laboratories
adauga mai tarziu acestuia cateva facilitati, numind noul produs UNIX
System V2, iar AT&T anunta oficial, in ianuarie 1983, versiunea System
V.
Specialistii de la Universitatea Berkeley din
California au cumparat in 1975, la fel ca multe universitati (cu suma de doar
400$ USD!) o banda cu sursele complete ale UNIX-ului. Ei au dezvoltat o alta
varianta a UNIX-ului, numita BDS - Berkeley Software Distribution.
O versiune celebra folosita azi pe calculatoarele VAX, pe care au numit-o BSD
4.3, furnizeaza o serie de proprietati noi si interesante, dintre care
trebuie remarcat software-ul de retea, care face calculatoarele UNIX usor de
conectat in retea.
Intre AT&T si specialistii de la Berkelei apar o
serie de frictiuni, in special in ceea ce priveste drepturile de autor.
AT&T formeaza UNIX Support Group (USG)
pentru dezvoltarea si comercializarea sistemului si declara propriul sistem ca
standard, si implicit sistemul BSD ca nestendard si incompatibil.
Pana la inceputul anului 1984 erau instalate in lume
aproape 100.000 de sisteme UNIX, realizate de diferite firme, care rulau pe
masini cu o gama larga a puterii de calcul, de la microprocesoare pana la
mainframe-uri. Intreaga industrie se bazeaza pe 2 versiuni de UNIX: Berkeley si
AT&T System V. Cel mai mare concurent neuniversitar pentru BSD este Sun
Microsystem. SUN OS se bazeaza pe versiunea BSD 4.1 si a fost dezvoltata de o
serie de absolventi Berkeley. O alta versiune de firma a lui BSD 4.2 a fost
Ultrix, sistemul UNIX care functioneaza pe masini DEC.
Pentru multe firme care au venit pe piata in anii '80
s-a pus problema alegerii UNIX-ului pe care sa-l adopte. Unii au optat pentruy
BSD, inclusiv din considerente de compatibilitate cu SUN. Altii au ales
AT&T System V, pe care AT&T l-a desemnat ca standard UNIX - este vorba,
de exemplu, de de Data Genera, IBM, Hewlet Packard, Silicon Graphics. O a treia
versiune de UNIX, numita Xenix, bazata pe AT&T System III, a fost
dezvoltata de Microsoft la sfarsitul anilor '90 si a fost inregostrata ca
licenta de Santa Cruz Corporation (SCO)
La sfarsitul anilor '90, deplasarea UNIX-ului din
domeniul tehnic si universitar in cel comercial a pus in prim plan compatibilitatea versiunilor de UNIX care ruleaza pe
diferite platforme. Primele doua versiuni care s-au unit, in 1988, au fost
Xenix si AT&T System V, sub numele de UNIX System V/386, release 3.12. Tot
in 1988, AT&T si SUN semneaza o intelegere de cooperar, prin care dezvolta
o versiune comuna de UNIX System V Release (SVR4). Este cel mai bun sistem
compatibil AT&T si Berkeley. De asemenea, SUN declara abandonul lui SUN OS
si demareaza realizarea lui Solaris.
Pentru a sustine producerea de versiuni compatibile,
in 1988, Apollo Computer, Dec, HP, IBM si alti trei 0producatori europeni
anunta formarea lui Open Software Foundation (OSF). Efortul de realizare a unui
sistem de operare propriu s-a materializat in OSG/1. care insa a aparut destul
de tarziu. Ca urmare, unele companii si-au realizat propriul UNIX (de exemplu
IBM a realizat AIX).
In 1993, AT&T vinde UNIX System Laboratories lui
Novel, care insa esueaza in realizarea unui sistemviabil pentru platforme PC.
Ca urmare, vinde proprietatea asupra
codului lui SCO, in 1995, moment in care dispare si USL.
Dec furnizeaza pe statiile sale o versiune UNIX numita
Digital UNIX (de fapt OSF/1), iar SUN comercializeaza statiile sale cu sistemul
de operare Solaris.
In ultimii ani, in special in mediile academice, se
foloseste Linux, o versiune free, dezvoltata de Torvard Linus, un tanar specialist
finlandez. In jurul ei este o mare efervescenta creatoare, dat fiind ca este
gratuita si contine toate sursele care pot fi dezvoltate sau modificate.
O serie de proprietati au determinat popularitatea si
succesul UNIX-ului:
Este scris intr-un limbaj de nivel
inalt, care-l face usor de citit, inteles, schimbat sau mutat pe alte masini.
Ritchie estima ca primul sistem in C era cu 20-40% mai mare si mai incet pentru
ca nu era scris in limbaj de asamblare, dar avantajele utilizarii limbajului de
nivel inalt depasesc mult dezavantajele;
Are o interfata utilizator simpla,
care poate furniza o gama larga de servicii;
Ofera primitive pentru constructia
unor programe complexe din programe simple;
Utilizeaza un sistem de fisiere
ierarhizat, astfel incat sa permita usor intretinerea si implementarea
eficienta;
Utilizeaza o forma consecventa a
fisierelor, facand programele usor de scris;
Furnizeaza o interfata asemenatoare
fisierelor pentru dispozitivele periferice;
Este un sistem multiuser,
multitasking; fiecare utilizator poate executa mai multe programe simultan;
"Ascunde" arhitectura masinii fata
de utilizator, facand programele usor de scris, indiferent de arhitectura
hardware.
Simplitatea si consecventa subliniaza valoarea
UNIX-ului si justifica multe din calitatile citate anterior. Desi sistemul de
operare si multe din programele de comanda sunt scrise in C, sistemul UNIX
suporta si alte limbaje, existand numeroase compilatoare si interpretoare.
In acest
capitol se vor prezenta pasii pe care i-a parcurs problema pe parcursul
definirii sale. Se porneste de la cerintele realitatii, si prin abstractizari
si relaxari succesive se ajunge la cerinte realizabile practic si definite
abstract, din care apoi se extrag cele mai importante, pentru a fi incluse in
specificarea cerintelor aplicatiei. Fiecare etapa urmareste limitari generale ale posibilitatilor unui motor de
cautare generic, probleme in realizarea unor anumite deziderate, posibile
rezolvari si compromisuri. Doar ultima etapa realizand simplificari care nu
sunt obligatorii in proiectarea oricarui motor de cautare. Astfel, penultimul
nivel poate fi folosit ca nivel de plecare pentru realizarea altor motoare de
cautare, care eventual sa implementeze si optiunile omise in aceasta aplicatie.
In plus, proiectarea incearca sa urmareasca si posibilitatile de adaugare a
altor facilitati, detectate ca posibile, dar excluse datorita raportului lor
mai mic intre imbunatatirea serviciilor si complexitatea realizarii.
Problema care se pune este realizarea unei aplicatii
care sa ajute la gasirea informatiilor pe WEB.
Aceasta cerinta isvoraste din volumul mare de informatii existent pe WEB, care genereaza imposibilitatea de
a cauta manual informatiile. Cautarea trebuie sa fie un serviciu permanent, sa
dea rezultatul in timp real (sau maxim cateva minute). Numai in cazuri
speciale, se pot accepta si intarzieri mai mari. Volumul de informatii este
atat de mare, incat nu se poate realiza o strangere a informatiilor intr-un
singur loc, unde cautarea sa sa se faca intr-un anumit fel. De aici rezulta
prima limitare:
Aplicatia nu
poate dispune local decat cel mult de rezumate ale informatiilor de pe WEB, impreuna cu referintele la
localizarea acestora. Aplicatia poate dispune bineinteles la orice moment de
intreaga informatie de pe WEB, dar viteza cu mult mai mica de transmisie a
datelor, face ca volumul de informatie care poate fi parcurs sa fie infim fata
de necesitatile clientilor. Numai in cazuri speciale, cautarea se poate face
direct pe Web. Acestea sunt cazurile in care se cunoaste localizarea
informatiei cu anumita precizie (se gaseste pe un anumit sit sau pe un grup mic de sit-uri)
sau cazurile in care importanta cautarii sa fie atat de mare incat sa se poata
sacrifica o perioada mai mare de timp, si bineinteles cautarea sa nu fie prea
urgenta. Folosirea generalizata a acestui tip de cautare insa este neproductiva, parcurgerea direct de pe
Internet a unui volum de date suficient de mare astfel incat sa fie gasita
informatia cautata fiind prea mare.
Astfel apare o limitare in modelul motorului de
cautare: este necesar ca cautarea sa se faca (si) intr-o baza de date deja
construita, actualizata permanent. Baza de date trebuie sa contina informatii
despre continutul si localizarea unei anumite resurse WEB. Aceste informatii pot fi extrase de motorul de cautare sau
prezentate de cel care este publica informatia respectiva pe Internet. In cazul
in care descrierea informatiei se face de catre cel care a publicat-o, exista
doua posibilitati: descrierea poate fi trimisa catre motorul de cautare (cal
mai fericit caz, dar mai putin probabil) sau poate fi facuta publica intr-un
mod special (META-TAG-uri), urmand ca in timpul parcurgerii motorul de cautare
sa o gaseasca si sa o includa in baza de date. Unitatea de prezentare a
informatiei pe WEB este pagina
web (pagina de text HTML care
contine informatie sau ofera accesul
la informatii de alt tip - imagini, sunet, video, programe, etc). In prezent, aceste informatii sunt
incluse in putine pagini web, ceea ce face necesara existenta unui mod
alternativ de extragere a informatiilor despre continutul paginilor web (prin
pagini web vom intelege si continutul informational de alt tip continut in
ele). Din cele spuse pana acum putem concluziona ca:
Un motor de cautare trebuie sa contina obligatoriu un
"motor de indexare" care sa parcurga (neincetat) WEB-ul si sa extraga informatii despre paginile web parcurse, si o
baza de date cat mai cuprinzatoare, in care sa se introduca informatiile
extrase, si in care sa se caute la cerere, in timp cat mai scurt, referintele
catre paginile web care contin (sunt susceptibile sa contina) informatia
cautata. Cautarea trebuie sa se faca continuu, pentru ca este putin probabil ca
un motor de cautare sa termine de parcurs macar 50% din WEB, si oricum, noi si noi pagini web apar, multe se modifica,
altele dispar.
Poate cea mai mare problema este ce sa extragi din
paginile web. Nu se poate extrage totul, asta este clar. In primul rand s-ar
putea extrage titlul paginii. Acesta da poate o oarecare informatie despre
continutul paginii, dar aceasta este
saraca si insuficienta. Apoi se pot extrage textele care duc la o informatie
(asanumitul "text senzitiv"). Acesta este si el uneori prea sarac, de
exemplu multe pagini sunt referite de textul "apasa aici" cu versiunea lui in
engleza - "click here" pentru textul senzitiv este precedat de un text de genul "Daca vrei sa
. .atunci". S-ar putea extrage si acel text, dar a automatiza asa ceva este
destul de greu, fiecare producator de pagini web adoptand propriile reguli de
aranjare a informatiei. Si un lucru este sigur: nu se poate cere producatorilor
de pagini web sa-si organizeze paginile intr-un anumit fel. Se pot doar
anticipa modele generale de organizare, care sa fie folosite in extragerea
informatiilor prezumptiv descripive si semnificative pentru continutul paginii.
Se pot extrage de exemplu bucatile de text formatate cu caractere mai mari sau
puse intr-un alt fel in evidenta, dar de multe ori efectul de "pus in evidenta"
se realizeaza numai cu concursul sensibilitatii umane, fiind greu depistabila
printr-un program. Nu se pot extrage nici concluzii despre continutul paginii
daca continutul nu este explicit stipulat in text. Folosirea de operatori umani
care sa aibe ca sarcina parcurgerea paginilor web si crearea de rezumate despre
acestea este nerealista prin lipsa ei de productivitate. De asemenea se observa ca datorita neinfailibilitatii
algoritmului de extragere a informatiilor descriptive despre paginile web,
cautarea nu poate da nici ea informatii de maxima incredere, ci cel mult poate
orienta subiectul uman care are nevoie de o informatie sa o caute intr-un numar
restrans de pagini, unde este susceptibila a se afla. Informatia continuta in
baza de date poate fi insa invechita si bineinteles ca exista pagini web care
nu au fost parcurse de loc.
Un motor de cautare este deci o aplicatie care da
informatii bazandu-se pe o euristica anume, si care nu poate garanta ca daca
informatia nu se gaseste in baza sa de date ea nu exista. Inainte de
prezentarea rezultatelor catre client
(cel care are nevoie de informatie) motorul de cautare poate intr-adevar
sa verifice daca paginile referite mai
exista si daca mai contin aceleasi informatii. Aceasta verificare este insa
consumatoare de timp, si de aceea de obicei motoarele de cautare nu o mai fac.
Nu se poate cere producatorilor de pagini web sa anunte modificarile pe care le
fac in pagini.
Se poate prevede ca in ciuda maririi vitezelor de
transfer in Internet, un motor de cautare nu va mai putea acoperii decat un
segment mic al Internetului. In afara de aceasta din cauza informatiilor prea
sarace care se pot extrage din pagini, o cautare are tendinta sa aibe ca
rezultat ori nici o pagina, ori un numar prea mare de pagini pentru a putea fi
parcurs de client. Astfel, volumul de informatii mare devine nefolositor. O
alternativa ar fi extragerea altor informatii despre pagina (de ex. segmentul
de adrese Internet de care apartine pagina, din care sa se extraga localizarea
geografica, limba in care este redactat textul, etc). Pentru marirea spatiului
bazei de date si pentru accelerarea cautarii se poate opta pentru distribuirea
bazei de date si/sau a spider-urlui
(denumire a partii unui motor de cautare care se ocupa de parcurgerea
paginilor). Cautarea se poate face cu cooperare, sau fiecare server poate fi
facut responsabil de un anumit domeniu (geografic de exemplu).
Una din problemele foarte importante este si
stabilirea modului de cautare, mai exact stabilirea formatelor in care se pot
face (si onora) cereri de cautare. Clientul are de obicei o sintagma care sa
descrie ceea ce cauta. Analiza semantica a respectivei sintagme este
nerealizabila (cel putin la momentul actual al progresului informaticii), deci
nu se poate spera decat ca sintagma exista in aceeasi forma in pagina cautata,
sau se poate cauta dupa cuvintele continute in sintagma. In acest caz
conjunctiile si alte elemente sunt total nefolositoare, fiind de fapt o cautare
dupa mai multe chei text. Apare insa si problema in care sintagma este
specificata intr-o limba, iar informatia este in alta limba. In afara cazului
cand se dispune de dictionare puternice, cererile trebuiesc facute cu cuvinte
din aceeasi limba cu cea in care sunt scrise paginile (care se spera a fi
gasite), si trebuie sa apara in pagina explicit (nu numai ca idee). Si asa, pagina
poate sa scape cautarii, cuvantul respectiv putand fi sarit la extragerea
informatiilor posibil semnificative. Trebuie luat poate in considerare si modul
de perceptie al clientului mai putin
famniliarizat cu functionarea unui motor de cautare, care se asteapta sa
gaseasca un oracol, caruia sa-i puna intrebari de genul "Unde gasesc si eu
pagini despre semanarea orzului si orzoaicei". Astfel de cereri pot fi onorate
ignorand pur si simplu din cautare cuvintele care reprezinta conjunctii,
prepozitii, articole, cuvinte fara semnificatie in general). Se pot realiza si
cautari complexe, dupa expresii regulate si combinarea lor in expresii logice,
dar practica arata ca aceste cautari aduc rareori beneficii, fiind si foarte
putin folosite de clienti. Cea mai folosita optiune este cea de cautare a
paginilor care contin un cuvant dat ca antet al altui cuvant (mod implicit de
cautare pe majoritatea motoartelor de cautare) si cautare de pagini dupa mai multe antete de cuvinte.
Aplicatia va trebui sa parcurga (indexeze) pagini web.
Adresele (referintele) acestor adrese vor fi specificate de catre autorii
paginilor sau in lipsa acestora, se vor indexa pagini referite din paginile
deja indexate. Aceste cerinte asigura functionarea permanenta a spiderului.
Pentru a controla intr-un mod mai judicios activitatea de indexare, se vor
indexa in paralel un numar de sit-uri, fiecare sit indexandu-se separat.
Astfel, o blocare a accesului la o pagina a unui sit produce automat anularea
temporara a indexarii sit-ului, pentru o data ulterioara. Se pot contoriza
astfel si numarul de pagini care se indexeaza pe un sit, considerand ca primele
cateva pagini contin referiri si despre celelalte, altfel fiind vorba de o
organizare defectuasa a site-ului. In acelasi timp se evita posibilitatea de
existenta a serverelor rauvoitoare care sa alimenteze cu pagini fictive sau sa
blocheze indexarea celorlalte pagini. Se pot proiecta apoi si alte moduri de
relationare a paginilor, ele fiind parcurse pe nivele (considerand un subarbore
al grafului cu radacina in pagina principala). Pentru asigurarea unuei comunicari eficiente si
rapide cu baza de date, vor rezultatele indexarii unui sit vor fi transmise
impreuna bazei de date.
Cererile (sugestiile) de indexare vor fi primite
printr-o intefata HTML/CGI, informatiile fiind puse intr-o coada de indexare
principala de catre un program. Va exista si o coada suplimentara, continand
referintele externe catre pagini web (pentru indexare in caz de lipsa de cereri
explicite de indexare). Coada principala va contine pentru fiecare
adresa-radacina de indexat tipul indexarii (se vor implementa mai multi
algoritmi), descriere initiala a paginii (specificata de cel care a comandat
indexarea sau obtinuta din textul senzitiv care pointa spre ea) si un contor al
numarului de incercari de indexare nereusite facute. Cat timp contorul nu
depaseste o anumita limita, pagina este resupusa indexarii la parcurgeri ulteriare ale cozii (coada este
reparcursa daca s-a ajuns la capatul ei si mai exista pagini carora nu le-a
reusit indexarea, altfel se citeste din coada suplimentara. Pentru adresel din
coada suplimentara nu se reincearca o indexare care a esuat). Nu este vorba de
o coada in sensul structurii de date cu acelasi nume. Este un spatiu in
care adresele asteapata sa fie
indexate, si in care se mentine si toata istoria indexarilor, pentru a se evita
indexari ale aceleiasi pagini de mai multe ori.
Aplicatia va trebui sa implementeze un "spider" care sa citeasca dintr-o coada
linii de informatie in format:
<nr
ori>^<URI>^<max nr pagini>^<descriere initiala>^<se
inregistreaza la>
unde:
<nr ori> = de cate ori se
reincearca indexarea paginii in cazul unui esec
<URI> = Adresa de localizare a paginii
de inceput pentru indexare
<max nr pagini> = numarul
maxim de pagini care se vor indexa pornind de la <URI>
<descriere initiala> = descriere data
de cel care initiaza indexarea sau textul senzitiv asociat adresei in caz ca
aceasta a fost gasita in alta pagina web.
Aplicatia
va pune de asemenea la dispozitie un program de adaugare de informatii la
aceasta coada, si o interfata HTML/CGI care sa foloseasca acel program in
"programarea" la indexare a adreselor. Aplicatia va trimite rezultatul
indexarii in format :
<URI
radacina> <lista campuri de
indexare>'n'
<separator><Urisubpagina1><separator><camp1,1><separator> . <separator><camp
1,K><separator>'n'
<separator><Urisubpagina1><separator><campM,1><separator> . <separator><camp
M,K><separator>'n'
unde
<separator><Urisubpagina1><separator><campM,1><separator> . <separator><camp
M,K><separator>'n'
este o lista de campuri separate de separatorul <separator>.
DE FACUT CA
LUMEA
Spider-ul reprezinta partea programului care se ocupa
de parcurgerea paginilor WEB si extragerea informatiilor considerate
semnificative pentru respectivele pagini. Desi depinde foarte mult de largimea
de banda a cailor de comunicatie, in perspectiva maririi vitezelor de
transmisie in Internet, trebuie sa asigure o viteza mare de procesare a
datelor. Trebuie asigurata o gestionare judicioasa a resurselor sistem, a
resurselor retelei si nu in ultimul rand a timpului de proiectare si
upgrade-are.
Resursele
retelei se pot gestiona mai judicios daca se relizeaza conexiuni la mai multe
site-uri in acelasi timp. Viteza de comunicatie este de fapt minimul vitezei de
comunicatie pe segmentele drumului intre masinile care comunica. Astfel, masina
indexatoare poate avea o largime de banda mare, dar ramurile care se desprind
din segmentul la care este conectata sa aibe viteze de comunicatie mult mai
mici. In acest caz, viteza atinsa in transferul catre mai multe site-uri este
aproximativ suma vitezelor cu fiecare site in parte. In cazul retelelor cu
comutarea de pachete, avantajele acestui
principiu sunt si mai evidente, mai multe conexiuni diferite insemnand
distribuirea automata a traficului. Apare deci ca o necesitate, stabilirea a
mai multe conexiuni simultan, mai ales ca se evita blocari in cazul in care un
site nu raspunde sau are viteza de comunicatie foarte mica. Conexiuni multiple
se pot realiza si intr-un singur proces, cu citire neblocanta, pe rand, circular,
din fiecare socket deschis. Datorita vitezei relativ mici de transmisie fata de
viteza procesorului, aceasta strategie duce la multiple apeluri sistem
"nereusite" - adica apel read() care intoarce E_AGAIN sau un numar foarte mic
de octeti. Este de preferat deci sa se lucreze cu mai multe procese, fiecare
facand apel blocant read(). Sistemul va ignora procesul pana va dispune de
destui octeti de informatie de transmis, astfel neirosindu-se timp CPU. In
afara de aceasta, solutia asigura o mai mare fiabilitate in exploatare, cum s-a
mai afirmat in sectiunile precedente. Datele vor fi stocate (intr-un fisier)
pana la indexarea totala a masinii, apoi se vor depune intr-un sistem de
asteptare al bazei de date, urmand a fi
adaugate. Nu este necesar ca datele sa fie depuse imediat in baza de date,
datorita faptului ca spider-ul nu se bazeaza pe informatii citite din baza de
date, astfel ca el nu trebuie sa fie "sigur" ca datele au fost introduse.
Singurii care "au de suferit" de pe urma intarzierii adaugarii in baza de date
sunt clientii care cauta, dar oricum informatia este o parte infima din baza de
date, si serverul de cautare nu da raspunsuri categorice de tipul "Nu exista in
Internet ceea ce cautati" ci raspunsuri partiale de tipul "Nu figureaza in baza
noastra de date ceea ce cautati". Datele vor fi adaugate in baza de date
imediat ce este posibil, asa ca aceasta mica relaxare a cerintelor nu produce o
scadere a calitatii serviciilor.
Pentru a face mai simpla adaugarea de noi strategii de
extragere a informatiilor din paginile WEB, modulul "indexare site" s-a
impartit in doua submodule, unul care sa extraga date esentiale pentru indexare
(link-uri, titlul paginii, metatag-uri) si unul care sa extraga informatii
suplimentare. Primul modul a fost proiectat modular, astfel incat tratarea unor
noi tag-uri sa fie usor adaugata. Al doilea modul poate fi chiar omis, el
constand in proiectarea unei reparcurgeri a fisierului download-at, solutie
aleasa pentru a nu fi restrictionata de tehnica de parcurgere a primului modul. Parcurgerea primului modul este
optimizata, rapida, astfel ca ramane de optimizat doar a doua parcurgere.
Download-ul se face intr-un unic fisier, rescris de fiecare data, deci putem sa
speram ca UNIX-ul il va retine pe parcursul parcurgerilor in ramdisk, deci
parcurgerea va fi foarte rapida.
Pemtru a indexa un site, este nevoie sa fie retinute
toate adrsele indexate deja de pe acel site, pentru a nu repeta indexarea lor
prin linkuri circulare. Aceasta lista este destul de mare, astfel ca mentinerea
ei in memorie este cam dezavantajoasa. Avand in vedere faptul ca accesul la ea
nu este foarte des, se va alege o implementare intr-un fisier. Lista de masini
nu va depasi insa o lungime prea mare, astfel ca o verificare liniara a
existentei in lista este acceptabila, spre deosebire de cazul in care s-ar fi
tinut o lista globlala a paginilor deja indexate. Eliminarea reparcurgerilor la
intervale de timp scurte se realizeaza prin politica de acceptare spre indexare
a site-urilor, cererile fiind destul de rare pentru ca o verificare liniara in
lista ultimelor N site-uri acceptate la indexare sa fie acceptabila.
Accesul la baza de date nu se face direct de catre
procesul indexator, ci printr-o zona de asteptare, care are rolul sa fluidizeze
accesul la baza de date si sa-l optimizeze, o conexiune la baza de date putand
astfel sa fie folosita pentru transmiterea de informatii despre mai multe
site-uri. Acest principiu face posibila si folosirea unui server de baze de
date care nu are implementat controlul
scrierilor concurente, concurenta citirii fiind gestionata de sistemul de
operare (daca acesta este UNIX). Din nou se poate accentua faptul ca o intarziere de cateva
minute/ore a inregistrarii unui site este nesemnificativa pentru scopul acestei
aplicatii.
Baza de date nu face parte din aplicatia prezenta, dar
se vor prezenta cateva considerente despre realizabilitatea ei si o posibila
strategie de implementare. Implementarea ei propriu insa nu va constitui
subiectul lucrarii de fata, care va realiza doar trasarea unor linii directoare
si stabilirea cerintelor bazei de date si a unei interfete aferente.
Baza de date trebuie sa fie de un tip special. Dimensiunile ei scot din cursa bazele
relationale, inplementarea ei trebuind sa se bazeze pe alta structura (eventual
pe structuri combinate). A realiza o corespondenta intre un cuvant si o
submultime a unei uriase multimi de adrese WEB nu este o sarcina usoara. Se
poate da teoretic orice cuvant din cateva limbi de circulatie internationala
folosite in submultimea de site-uri indexate. Se vor excepta de la inregistrare
bineinteles cuvintele cuvintele care nu au un continut semantic propriu
(conjunctii, articole, pronume). Daca facem abstractie de spatiul necesar
memorarii, simpla problema de identificare a multimii de site-uri asociate unui
cuvant este (din cauza numarului urias de cuvinte) o problema serioasa de
proiectare. O cautare liniara in spatiul de cuvinte este exclusa. Chiar si o
dispersie dupa carteva litere pare insuficienta. Aranjarea intr-un arbore de
sortare sau B-arbore pare a fi solutia. Arborii de sortare sunt destul de
costisitori ca spatiu de memorie, deci o strategie asemanatoare B-arborilor ar fi mai nimerita. De fapt un
B-arbore functioneaza static ca un arbore exchilibrat care realizeaza dispersii
succesive asupra elementelor sale. Nivelele sale sunt nivele de dispersie,
primul nivel realizand ramificarea dupa o anumita functie de dispersie , al
doilea realizand o dispersie a multimilor dupa care a fost dispersat nivelul
anterior, etc. Dinamic, un B-arbore functioneaza ca o dispersie succesiva
dinamica. Cerintele de echilibrare a arborelui pot fi relaxate la cerinta unei
echilibrari aproximative, pentru a realiza o medie a lungimii drumurilor de la
radacina la frunze cat mai mica. In cazul cuvintelor putem folosi anumite
caracteristici probabilistice ale lor. De exemplu, cuvintele unei limbi au o
lungime medie nu mai mare de 10 caractere (de exemplu in sectiunea II a acestei
lucrari media lungimii cuvintelor de pana acum este de 5-6 caractere, dar o vom
considera mai mare pentru ca la indexare se vor elimina cuvintele de lungime
mai mica de 3-4 caractere, si anumite cuvinte mici care se gasesc prea des in pagini - conjunctii, etc). De asemenea,
dispersia lungimii cuvintelor este destul de mica. Daca am realiza un arbore in
care radacina (nivel 0) sa duca la toate cuvintele, iar fiecare subarbore de
nivel k 1
sa aiba asociata o submultime a nivelului k-1 obtinuta prin dispersie dupa a
k-a litera a cuvintelor , aceste arbore ar fi destul de apropiat de cerintele
noastre. Daca vom pastra din cuvinte cel mult M caractere (de exemplu M=20) vor
obtine un arbore cu cel mult 20 de nivele, fiecare nivel avand o ramificare de
cel mult 128. Chiar si in aceste conditii limita, foarte departate de situatia
reala, gasirea intrarii asociate unui cuvant va lua cel mult 20*128=2560
operatii. Numarul 128 este exagerat insa, putand pune restrictia ca un cuvant
este format numai din cele mai putin de 30 de litere ale unui alfabet, diferenta cuvintele nefiind
considerate case-sensitive. De obicei numarul literelor care pot urma imediat
dupa un antet de cuvant, astfel incat cuvantul format sa fie antet al unui
cuvant al unei limbi nu acopera numarul total de litere ale alfabetului, existand
limitari si in privinta posibilitatii de pronuntie a respectivului antet creat.
Aceasta strategie deci pare a oferi un timp de cautare sub o limita
acceptabile, iar pe parcursul adaugarii de cuvinte, arborele va devenii tot mai
echilibrat (din cauza distributiei relativ uniforme a cuvintelor). Se poate
deci renunta la cerinta de echilibrare dinamica a arborelui (cum se face la
B-arbori), costul de timp la cautare
fiind surclasat de economia de timp facuta prin eliminarea reechilibrarilor.
Acest index al cuvintelor (implementat ca un arbore de
exemplu) are dimensiuni foarte mari, deci va fi implementat in cel putin un
fisier. Daca consideram ca fiecare multime de site-uri referite de un cuvant
este este stocata intr-un fisier, insasi complexitatea deschiderii acestui
fisier devine o problema. Daca toate aceste fisiere sunt stocate intr-un
director, banalul open() va trebui sa faca o cautare (foarte probabil liniara)
in directorul respectiv, rezultand o cautare de ordinul numerului de cuvinte
din baza de date. Mai apare apoi si problema maximului de fisiere admise
intr-un director. Apare deci necesitatea ca o dispersie asemanatoare sa fie
facuta si in cazul fisierelor, deci ele sa fie situate intr-o arborescenta cat
de cat echilibrata. Pentru a nu realiza o munca dubla (de timp implementare si
la executie), dispersia se poate implementa (macar pe primele nivele) chiar in
structura de directoare. Dispersia poate fi facuta dupa N=2-3 caractere, numele
directoarelor reprezentand grupul de caractere dupa care s-a facut dispersia pe
nivelul curent. Pornind dintr-un director radacina, vom avea deci directoare cu
nume format din N litere care reprezinta
antete valide de cuvinte. Fiecare director va contine fisierele asociate
cuvintelor care incep cu respectivul antet. Daca undeva in aceasta arborescenta
vor fi fisiere asociate cuvintelor care incep cu w, subdirectoarele sale numite xxx
vor contine fisiere asociate cuvintelor wxxx.
Problema cuvintelor incheiate care nu au ca lungime un multiplu al numarului de
caractere dupa care se face dispersia pe un nivel si a celor care sunt antete
ale altor cuvinte mai lungi va fi tratata prin stabilirea unor conventii
speciale. In acest fel se realizeaza un sistem simplu de proiectat, usor de
depanat si care inlatura dezavantajele cresterii complexitatii rezolvarii
path-ului fisierelor.
Alternativ la aceasta strategie se poate face
comasarea dupa cateva nivele de dispersie a referintelor intr-un singur fisier,
in care cautarea sa se faca in alt mod.
De asemenea, pastrarea pentru un cuvant a tuturor
paginilor in care apare este destul de costisitoare ca spatiu disk, deci se
poata face o dispersie a adreselor de pagini dupa site-ul (numele masinii) pe
care se afla. Un cuvant va pointa deci catre un site, presupus destul de mic
pentru a se cauta pe el paginile in care se gaseste cuvantul. Astefel, aparitia
unui cuvant in toate paginile nu va produce decat o referinta, spatiul
economisit fiind extrem de mare. In acelasi timp, se poate observa ca anumite
cuvinte tind sa se gaseasca in anumite tipuri de site-uri, insasi numele
site-ului fiind o informatie destul de specifica uneori pentru gasirea
informatiei cautate, mai ales ca site-urile sunt din punct de vedere logic
structurate ca un intreg, si o buna proiectare a lor trebuie sa asigure o
regasire simpla a informatiilor. In informatiile stocate despre un site se
poate cauta si liniar, neexistand alte strategii de cautare mult mai performante atata timp cat numarul de
pagini indexate de pe un site este rezonabil, ceea ce spider-ul va si realiza,
avand in vedere ca pe un site, subarborele paginilor ar trebui sa ofere dupa
cateva nivele o impartire pe subdomenii
destul de inguste astfel incat sa se poata decide daca informatia se gaseste
sau nu intr-un anumit subarbore (subgraf).
Cautarea se va raliza deci in general prin gasirea
site-urilor in care se gasesc cuvantele cheie dupa care se cauta, cautarea
facandu-se in intersectia lor. Informatiile despre un site se pot memora
intr-un fisier, fisierele fiind pentru acces mai rapid puse intr-un arbore, in
care sa fie dispersate dupa numele de domeniu si subdomeniu din sitemul de nume
de domenii DNS, ceea ce face simpla si stergerea sau mutarea unui domeniu.
Cautarea intr-o submultime de site-uri are ca
principiu asocierea la un cuvant a unui numar rezonabil de site-uri. Pentru
cuvintele care au un numar foarte mare de site-uri asociate, putem gasi de
cuviinte sa-l consideram nesemnificativ, deoarece nu ingusteaza destul de mult
spatiul de cautare. Aceste cuvinte le putem deci exclude din indexare, fiind si
singura metoda de a elimina cuvintele mai mari de 3-4 caractere care sunt
nesemnificative pentru cautare. O alternativa ar fi folosirea unui dictionar de
cuvinte comune, dar acest dictionar trebuie sa acopere un numar mare de limbi, si momentan nu exista
asa ceva. In afara de acestea, exista familii de cuvinte care se gasesc intr-un
numar mic de site-uri, si care apar in toate variantele sale (ex: chirurgie, chirurg, chirurgical). Am putea sa gasim o
strategie prin care cuvintele care au aceeasi radacina si care pointeaza la un
numar mic de site-uri sa nu pointeze fiecare la multimea lui de site-uri, ci
radacina lor sa pointeze la reuniunea acestor site-uri. In acest fel se elimina
redondante suparatoare si se face o mare economie de spatiu. Exista si un mic
inconvenient: dupa gasirea site-urilor asociate unui cuvant vom gasi o multime
de site-uri marginita de o limita prestabilita, dar nu vom avea certitudinea ca
cuvantul se afla efectiv in toate aceste site-uri. Este teoretic posibil sa nu
se afle in nici unul din site-uri, gasindu-se doar un subcuvant al sau. Totusi,
limitarea garantata a numarului de site-uri face ca la o cautare sa se poata
raspunde in timp util cu TOATE paginile in care se gasestc cuvintele cheie
specificate, sau se poate descoperi ca in baza de date nu exista cuvantul
respectiv. O problema mai apare si la implementare. In acest caz trebuie facuta
o dispersie dinamica a site-urilor. Se va pleca cu o dispersie vida, toate
site-urile fiind intr-o categorie. Cautarea aricarui cuvant in index va da ca
raspuns toate site-urile curent indexate, in numar mai mic de o limita MAX.
Aceasta limita va fi aleasa destul de mica astfel incat sa fie posibila o
parcurgere a informatiilor asociate respectivelor site-uri, chiar liniar. Dupa ce numarul elementelor dintr-o categorie
a depasit limita, se va face o dispersie a categoriei dupa inca cateva litere
N=2-3. Cuvintele incheiate (nu mai au litere dupa care sa fie facuta dispersia)
vor avea asociata cate o multime de site-uri. Celelate vor fi dispersate dupa
inca N litere. Astfel, fiecare categorie va avea asociat o lista de cuvinte de
N litere reprezentand dispersiile succesive dupa al K-ulea N grup de litere,
unde K reprezinta nivelul de dispersie. Concatenarea acestor cuvinte formeaza
antetul comun tuturor acestor cuvinte si numai al lor. Cautarea se va face deci
prin cautarea celui mai lung antet existent in arborele de dispersie. Daca prin
gasirea antetului se ajunge la o frunza a arborelui, exista doua posibilitati:
frunza poate fi o lista a site-urilor care contin cuvinte cu acel antet, caz in
care se raspunde cu aceasta lista, fie frunza va reprezenta un cuvant incheiat,
caz in care daca cuvantul incheiat gasit este cuvantul cautat se raspunde cu
acea lista, altfel se raspunde cu lista vida. Daca antetul gasit "epuizeaza
cuvantul" (este chiar cuvantul) si pe nivelul la care s-a ajuns nu exista
frunze (antetul nu este cuvint incheiat si nu este destul de semnificativ -
numarul mare de referinte a facut ca respectiva categorie sa se disperseze inca
un nivel), atunci se raspunde cu lista vida de site-uri, ceea ce inseamna ca nu
exista nici un o inregistrare in baza de date care sa contina respectivul
cuvant. Problemele de implementare care apar sunt la dispersia unei liste
dispersate atunci cand ea depaseste o anumita lungime. Exista doua
posibilitati: ori sunt mentinute in fiecare categorie si lista de cuvinte care
au un respectivul antet si corespund la site-urile din lista, caz in care
dispersarea dupa inca cateva caractere este simpla, dar redondanta este foarte
mare (cuvantul figureaza si in informatiile despre site), ori nu sunt mentinute cuvintele, dispersia
trebuind efectuata prin gasirea in site-urile din lista a cuvintelor cu acel antet,
si redispersarea lor dupa inca N litere. Varianta a doua nu poate "exploda" ca
timp de executie, numarul de site-uri in care se face cautarea cuvintelor fiind
controlat de limita MAX folosita si pentru a limita numarul de siteuri in care
se face cautarea.
Pentru a realiza un compromis intre spatiu si volumul
de informatii referite, pentru un cuvant incheiat se poate face retinerea numai
a ultimelor LAST referinte (cronologic), pe principiul ca odata cu trecerea
timpului informatia poate sa nu mai fie valabila. Aceasta salveaza si spatiul disk
necesar pana se aduna destule site-uri-referinta la un cuvant pentru a fi
considerat nesemnificativ, caz in care referintele se vor sterge.
O problema este si stergerea unor site-uri indexate de
prea mult timp, eventual pentru a il reindexa. Cuvintele din respectivul site
trebuie reextrase, pentru a fi deduse din index. Daca se sterg destule
site-uri, un cuvant poate sa piarda toate referintele, devenind din
nesemnificativ semnificativ sau facand posibila si de dorit o restrangere a
categoriilor vecine intr-o singura categorie. Restrangerea poate fi omisa, cu
pierderi de spatiu, dar problema stergerii unei categorii vide sau schimbarii
incadrarii din punct de vedere al semnificatiei a unui cuvant (ca urmare si a
cresterii pragului de semnificatie) sunt probleme demne de luat in seama.
Stergerea unei categorii vide este simpla, iar schimbarea incadrarii unui
cuvant de la nesemnificativ la semnificativ se poate face prin testarea la
fiecare incercare de adaugare a unei referinte a relatiei intre numarul de
referinte curente si pragul de semnificatie. Se vor pierde bineinteles
referintele de inainte de a redeveni semnificativ. Trebuie insa sa se pastreze numarul de
referinte ale cuvantului (ori ca numar de siteuri in care apare, ori ca numar
de aparitii in pagini, depinde de strategie - aceesi strategie se va aplica si
la stergere).
O idee buna este si realizarea unei scheme de
identificare a masinilor, pentru a identifica numele unei masini (de 10-20)
caractere cu un numar reprezentat pe doar 4-6 caractere. Astfel, se va
economisi spatiu de memorare la aparitiile multiple ale numelui unei masini.
Este important insa ca obtinerea unuia din identificatorii de masina din
celalalt sa se faca usor, mai ales obtinerea numelui real al masinii din
identificatorul prescurtat.
IMPLEMENTAREA
Aplicatia poate fi impartita in doua parti, separate
din punct de vedere logic. Aceste parti ar fi "spider-ul" (motorul de cautare
propriu zis, care realizeaza parcurgerea paginilor si extragerea informatiilor)
si baza de date, care trebuie sa stocheze informatia extrasa si sa ofere
diferite tipuri de cautari in informatia stocata. Pentru a imparti volumul de
calcul aceste doua parti pot lucra chiar pe masini diferite, de aceea pare a fi
potrivit sa alegem ca mod de comunicare intre ele socketurile AF_INET, care
functioneaza bine si in comunicatiile intre procese de pe aceeasi masina.
Implementarea unui motor de cautare nu trebuie sa
satisfaca numai cerintele de viteza si spatiu de memorie scazut. Se presupune
ca motorul de cautare va fi sub "foc continuu", el trebuind sa functioneze
neintrerupt mult timp. Datorita faptului ca aplicatia prelucreaza date in
format foarte liber, este destul de probabil sa se poata gasi date de catre
rauvoitori care sa "incarce" aplicatia, sau chiar sa produca erori in
program. Experienta arata ca si
programatorii experimentati pot face greseli in C, deci aplicatia trebuie sa
fie proiectata in asa fel incat o problema aparuta intr-o anume regiune a
programului sa nu afecteze celelate regiuni care pot lucra independent de ea.
Portiunile critice (de care depind toate celelalte regiuni) pot fi simplificate
astfel ca pot fi proiectate cu un grad de siguranta mai mare. Asta nu inseamna
desigur ca la celelate module de program nu se va face o verificare stricta a
datelor. Din aceste considerente, pare nimerit sa se aleaga o distribuire a
activitatii intre mai multe procese, fiecare ocupandu-se cu indexarea paginilor
de pe un anumit site. Daca un rauvoitor incearca sa trimita date aberante, in
exces, el va putea bloca cel mult procesul care se ocupa de sit-ul sau,
putandu-se continua normal indexarea celorlalte sit-uri. Prin aceasta strategie
se pot controla si mai usor erorile temporare aparute la indexarea unui sit. De
exemplu, daca un sit este momentan inaccesibil, sau daca name-serverul de care
apartine nu poate rezolva adresa, se suspenda indexarea intregului sit, urmand
a se incerca ulterior inca o indexare. De asemnea, se poate realiza o mai buna
comportare in caz de caderi de tensiune sau de sistem. Daca o masina nu a fost
indexata total, se va incerca reindexarea ei de la inceput. Astfel se evita
pierderile de date sau (mai rau) datele eronate care puteau sa se intample la
indexarea incompleta. Informatia despre un sit se pastreaza separat de a altor
sit-uri, trimitandu-se la baza de date la sfarsitul indexarii. Perioadele
critice (intre trimiterea catre baza de date a informatiilor despre un sit si
inregistrarea pe hard-disk a faptului ca sit-ului a fost indexat complet) sunt
foarte mici, probabilitatea ca o cadere de tensiune sa provoace pierderea
informatiei ca sit-ul a fost indexat total si rezultatul trimis la baza de date
este extrem de mica. Informatia trimisa la baza de date este mai mare,
realizandu-se o utilizare judicioasa a resurselor bazei de date si a unei
eventuale eventuale conexiuni TCP/IP. Aceasta arhitectura da posibilitatea si
de a adauga diferite euristici de extragere a informatiilor despre un sit care
sa ia in considerare mai mult de o pagina, de realizare a unor statistici de cuvinte pe un sit, care sa fie folosite
ca criterii de cautare. Se realizeaza de asemenea si centralizarea erorilor
gasite intr-un sit si a problemelor dubioase aparute la indexarea sit-ului (referinte
inexistente, erori de sintaxa in pagina), putandu-se trimite prin e-mail
producatorului sit-ului o evidenta a erorilor gasite. Modulul de indexare sit
poate fi folosit si la realizarea unui serviciu special, de cautare pe un sit a
unei anumite informatii, serviciu care poate fi folosit ca serviciu alternativ
al motorului de cautare, sau poate fi implementat in interiorul unui anumit sit
nededicat cautarii. Daca mai adaugam simplitatea si eleganta programarii,
aceasta strategie pare cea optima.
Modulul
principal (din punct de vedere al dependentei modulelor) ar trebui sa fie
modulul de gestiune al indexarii sit-urilor. El trebuie sa lanseze in executie
procesele de indexare sit, sa controleze incarcarea sistemului (de fapt numarul
de procese lansate in executie la un
moment dat), sa contabilizeze rezultatul incercarii de a indexa un anumit sit
si numarul de incercari. El trebuie sa fie un proces daemon care sa lanseze
procesele de indexare si sa astepte apoi in apel sistem wait() terminarea unui
proces fiu lansat. Cozile de sit-uri de indexat vor fi implementate intr-un fisier, datorita dimensiunilor mari
la care pot ajunge si datorita nevoii de a rezista unei caderi de tensiune.
Scrierea in coada se va face concurent cu un program special pus la dispozitie,
care va face write(), astfel asigurandu-se neinterclasarea informatiilor in
cazul scrierii concurente. In cazul in care indexarea s-a terminat cu succes,
gestionerul indexarilor va semna sit-ul respectiv ca indexat. In caz contrar va
decrementa numarul de incercari de indexare care vor mai fi facute. Strategia
de reindexare este urmatoarea: daca in coada sunt sit-uri de indexat, se face
indexarea lor; daca s-au epuizat toate sit-urile din coada, se reia indexarea
cozii de la inceput, incercandu-se sa se indexeze sit-urile ramase neindexate;
daca nu a mai ramas nici un sit de indexat, se trece la indexarea sit-urilor
dintr-o coada suplimentara, formata din sit-uri poinatate de sit-urile deja
indexate; in caz ca si aceasta coada s-a epuizat (extrem de putin probabil) se
asteapta adaugarea unui alt site in coada principala. Offset-ul la care s-a
ajuns cu citirea din coada va fi scris permanent si intr-un fisier, pentru a asigura reinceperea indexarii dupa
repornirea aplicatiei din locul in care
s-a ramas.
Se va implementa de asemenea un modul "get_url" care
va realiza incarcarea unei pagini web, care va avea ca sarcina si tratarea anumitor redirectari
posibile in protocolul HTTP. Functia get_url va avea ca argumente si numarul de
secunde la care sa renunte la incarcarea paginii si dimensiunea maxima a
informatiei pe care o va accepta de la serverul HTTP - pentru a evita blocarea
conexiunii sau generarea de informatii la infinit de catre un rauvoitor.
Modulul principal pentru parcurgerea unui site este
functia parcurgere_recursiva() care implementeaza o coada in care se face
stocarea linkurilor pentru parcurgerea in latime al grafului de legaturi al
unui site. Modulul pune la dispozitie o functie pun_la_recursie() care prin
care se adauga o informatie in coada. Functia parcurgere_recursiva() citeste
din coada initializata anterior de program cu pagina de start. Apeleaza functia
geturl() si in cazul incarcarii cu succes a paginii, apeleaza functia
extrlinks() care parcurge fisierul. Functia extrlinks() identifica blocurile
HTML <title> (titlu), <A>(ancora), <frameset>(URL-ul asociat
frame-ului), <meta>(informatii
despre pagina, cuvinte cheie, descriere). Pentru fiecare bloc gasit, extrage si
formateaza informatia utila si o trimite la o functie specializata care o
valorifica (se seteaza titlul paginii curente, se adauga in coada de indexare
noile link-uri gasite impreuna cu textul lor senzitiv corespunzator, se adauga
descrieri extrase din taguri <meta>. Dupa parcurgere, procesul de
indexare se reia ca mai sus, cu urmatorul link din coada (daca exista si nu s-a
depasit numarul de link-uri indexate).
Functia geturl() foloseste functia conect() pentru a
deschide o conexiune TCP/IP, ea avand rolul de a comunica cu serverul WEB prin
protocolul HTTP/1.1, tratand si erorile generate de aceste (document mutat, caz
in care face automat incarcarea URL-ului
indicat ca noua locatie).
Pentru cautarea rapida intr-o lista, s-a implementat o
citire cu buffer de dimensiune variabila, buffer in care se face si o cautare
optimizata a unui sir. Acest sistem se
foloseste atat la cautarea rapida a tag-urilor in paginile WEB cat si la
verificarea existentei unui anumit URL in coada de indexare.
S-a implementat de asemenea o biblioteca de erori, cu
4 tipuri functii, fiecare pentru afisarea a cate un tip de erori. Erorile se
impart in doua categorii dupa gravitatea lor : nefatale - "warning" si fatale
"error". Fiecare categorie se subimparte in doua categorii: erori cauzate de
functionarea programului si erori cauzate de datele primite de la cel care a a
cerut indexarea sau a datelor citite de pe site-ul respectiv. Aceste date se
pot astfel trimite prin e-mail celor interesati (client sau administrator
sistem). Biblioteca are o interfata simpla, asemanatoare lui printf, permitand
afisarea formatata a textelor si datelor care pot fi utile in clarificarea
mesajelor de eroare. Biblioteca foloseste tehnica de transmitere a unui numar
variabil de argumente, folosind intern sprintf(), si write pentru scriere. Prin
scrierea fara buffer, la o eventuala cadere a sistemului ultimele erori sunt
scrise, ceea ce nu s-ar intampla in cazul scrierii cu fprintf.
Partea
III
Anexe
Andrew S. Tanenbaum: Retele de
calculatoare (editia a treia), Computer Press AGORA (1998)
Victor-Valeriu Patriciu, Monica
Pietrosanu-Ene, Ion Bica, Costel Cristea: Securitatea informatica in UNIX si
INTERNET , Editura tehnica (1998)
Marshall Wilensky & Candace
Leiden , TCP/IP pentru toti, Editura Teora (1996)
Iosif Ignat, Adrian Kacso: Unix -
gestionarea proceselor, Editura Albastra (1995)
V. Cristea, A. Paunoiu, E. Kalisz,
I. Athanasiu, L. Negreanu, S. Calinoiu, F. Baboescu: UNIX, Editura Teora (1993)
Vasile Petrovici, Florin Goicea:
Programarea in limbajul C, Editura Tehnica (1993)
Dan Somnea, Doru Turtulea: Initiere
in C++ - programarea orientata pe obiecte -, Editura Tehnica (1993)

